Work/개발 노트
[KANS] 4주차 - Service (ClusterIP, NodePort)
★용호★
2024. 9. 28. 17:10
개요
- Service는 쿠버네티스에서 동작하는 애플리케이션을 내/외부에서 유연하게 접속하기 위한 역할을 하며 ClusterIP, NodePort, LoadBalancer Type을 지원
- Service 동작에 중요한 부분을 차지하는 것이 kube-proxy 인데 kube-proxy의 ConfigMap을 보면 기본으로 iptables를 사용하는 것으로 설정되어 있음
- 참고로 Amazon EKS는 kube-proxy의 ConfigMap이 간소화되어 설정되어 있고, 기본값이 iptables이기 때문에 굳이 명시되어 있지 않음
- Pod는 재생성 되면 매번 IP가 변경되기 때문에 클라이언트 입장에서는 매번 IP가 바뀌면 문제가 되기 때문에 Service 개념이 필요함
- 고정 Virtual IP를 할당하고 Domain 주소를 생성해서 클라이언트에서 도메인으로 접근 가능하도록 함
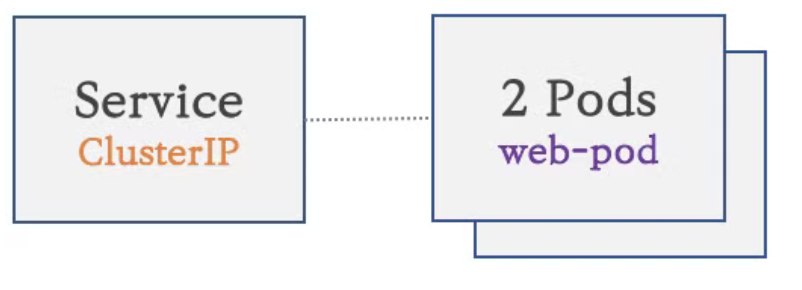
- 이렇게 생성되는 구성을 ClusterIP라고 하는데 외부에서는 ClusterIP로 생성된 Service의 도메인에 접근이 불가능
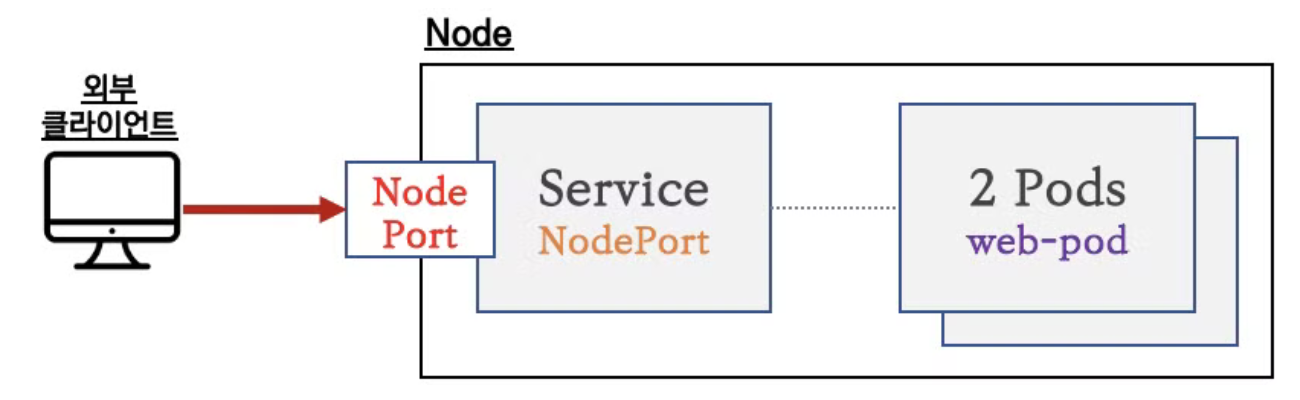
- 외부에서 가능하도록 하기 위한 것이 NodePort
Tips) Service는 어떻게 연결된 Pod들을 알 수 있을까?
- 서비스에 연결된 Pod의 집한은 레이블과 셀렉트로 서비스 리소스에 설정됨
- 레이블은 관리 목적으로 Pod를 포함한 쿠버네티스 내 리소스들에 메모를 작성한다고 볼 수 있음 (예 - app=web)
- 셀럭터는 설정된 레이블 값을 가지고 있는 리소스들을 선택할 수 있도록 함. 이런 레이블과 셀렉터의 조합으로 서비스는 연결된 대상 Pod들을 알 수 있음
ClusterIP
- Service를 ClusterIP로 생성하게 되면 마치 로드밸런서 역할을 하는 것 같은 가상의 IP와 도메인명을 가진 Service가 만들어지는데 이 때 서비스에 매핑된 Pod들의 IP로 트래픽이 전달될 수 있도록 모든 노드들의 iptables의 Rule이 갱신됨
- ClusterIP 사용 시 서비스에 연동된 Pod 갯수 퍼센트(%)로 랜덤 분산과 세션 어피니티를 사용하는 것 외에 다른 분산 방식은 없음
- IPVS를 사용할 경우 다양한 분산 방식(알고리즘) 사용 가능
iptables

- 모든 리눅스 서버의 OS는 커널과 애플리케이션으로 나눌 수 있음
- 커널 영역 : 운영 체제 실행을 위해 필요한 메모리 공간
- 사용자 영역 : 애플리케이션이 동작하기 위해 사용되는 메모리 공간
- iptables는 호스트의 방화벽/NAT 역할을 수행하며 사용자 영역에서 동작하는 iptables에 정책 설정 시에 커널 영역에 내장된 넷필터 리눅스 커널 모듈을 통해서 실제로 통제를 수행함
- Pod간 통신을 하기 위한 라우팅 정보가 호스트의 라우팅 테이블에 추가되지 않음. 해당 Pod의 Ip와 port로 리스닝하고 있지도 않음. iptables rule에 정의된 대로 netfilter에 의해 트래픽이 전송되고 pod의 네트워크 네임스페이스는 격리되어 있기 때문에 해당 pod 안에서만 리스닝하고 있으면 됨 (호스트와 pod간에는 veth pair로 연결되어 있기 때문에 통신 가능)
- 서비스 통신 설정에 대한 관리를 위해 kube-proxy가 존재하며, 유저 스페이스 proxy 모드, iptables proxy 모드, IPVS proxy 모드가 있음 (최근에 nftable 모드도 지원)
- 유저 스페이스 proxy 모드는 필터와 NAT처리를 사용자 영역에서 실행하기 때문에 커널과 사용자 영역간 왔다갔다 하는 오버헤드가 있음. kube-proxy에 문제가 발생하면 통신이 불가능하기 때문에 SPOF 문제도 있음
- 쿠버네티스는 기본으로 iptables proxy 모드를 사용함. 이 때는 트래픽 수신 시 넷필터에서 바로 대상으로 라우팅함. kube-proxy에 문제가 생기더라도 넷필터에서 트래픽을 관리하기 때문에 SPOF 문제가 발생하지 않음
- IPVS proxy 모드는 넷필터에서 동작하는 L4 로드밸런서로 iptables 보다 좀 더 성능이 높고, 규칙 갯수를 줄일 수 있음 (실무에서 가장 권장하는 방식)
- IPVS도 iptables를 사용하긴 하지만 kernel IPVS를 같이 사용함
- iptables와 달리 hash 테이블을 사용하기 때문에 성능 이점이 있음. iptables는 클러스터 규모가 커지면 구조적으로 느려질 수밖에 없는 환경이라서 일정 규모 이상으로 클러스터가 커지면 IPVS 모드로 변경할 것을 권장함
- nftable 모드는 iptables를 사용하지 않고 nftable API를 사용함. iptables의 구조적인 성능 저하 문제를 해결하기 위해 최근에 나온 방식
- 기존에 iptables를 사용했었다면 nftable로 마이그레이션 할 때 고려할 사항들이 있음 (호환 안되는 부분들이 있음)
- Cilium의 경우에는 kube-proxy 없이 Cilium 자체적으로 해당 역할을 모두 수행하고 있고, 다른 CNI 들에서도 점점 기능이 확장되다보니 최근에 kube-proxy가 공식 문서에도 optional로 변경됨

Tips) eBPF란?
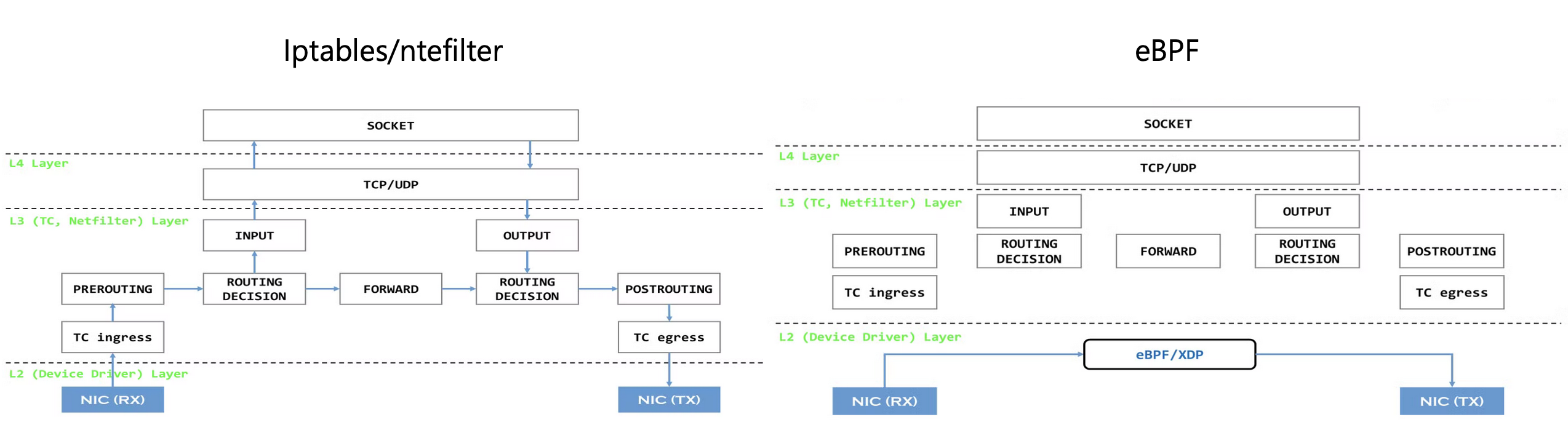
- 왼쪽 그림처럼 iptables를 사용할 경우 트래픽이 들어오면 netfilter의 여러 훅들에 의해 트래픽이 필터 또는 NAT 되어 라우팅 되는데 예를들어 소켓 통신인 경우에는 INPUT을 통해 사용자 영역의 애플리케이션으로 패킷이 전송되고 처리 된 후에 OUTPUT과 POSTROUTING을 거쳐서 호스트의 네트워크 인터페이스를 통해 응답을 보내게 됨
- 이 과정에서 발생하는 오버헤드를 줄이기 위해 eBPF는 하드웨어 layer에서 바로 패킷에 대한 처리를 해서 목적지로 포워딩 하기 때문에 성능을 향상 시킬 수 있게됨
- 대표적으로 Cilium에서 eBPF를 사용해서 쿠버네티스 클러스터 내 트래픽을 관리함
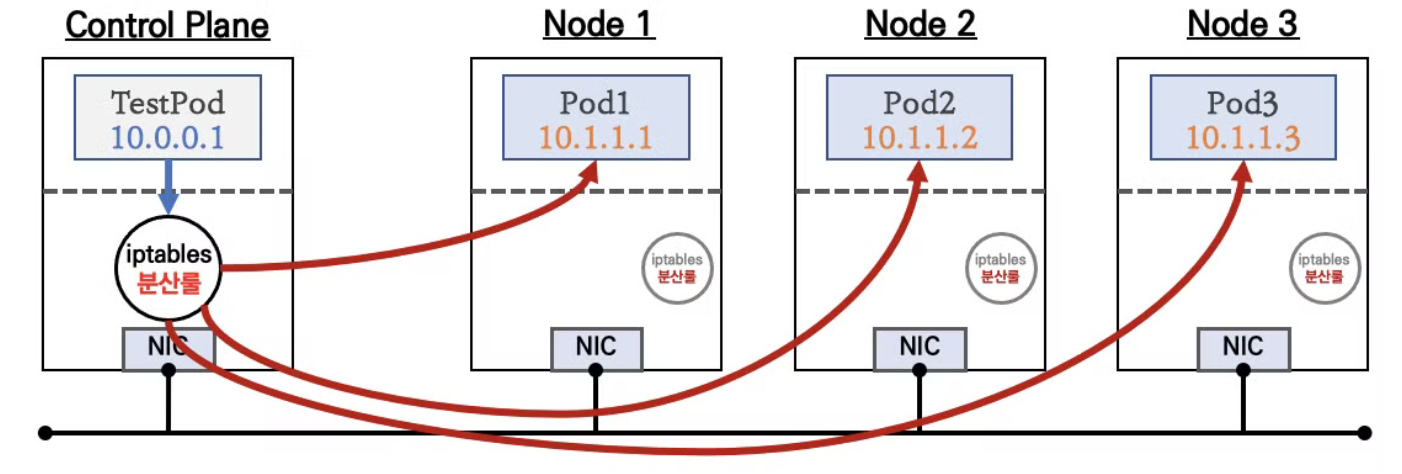
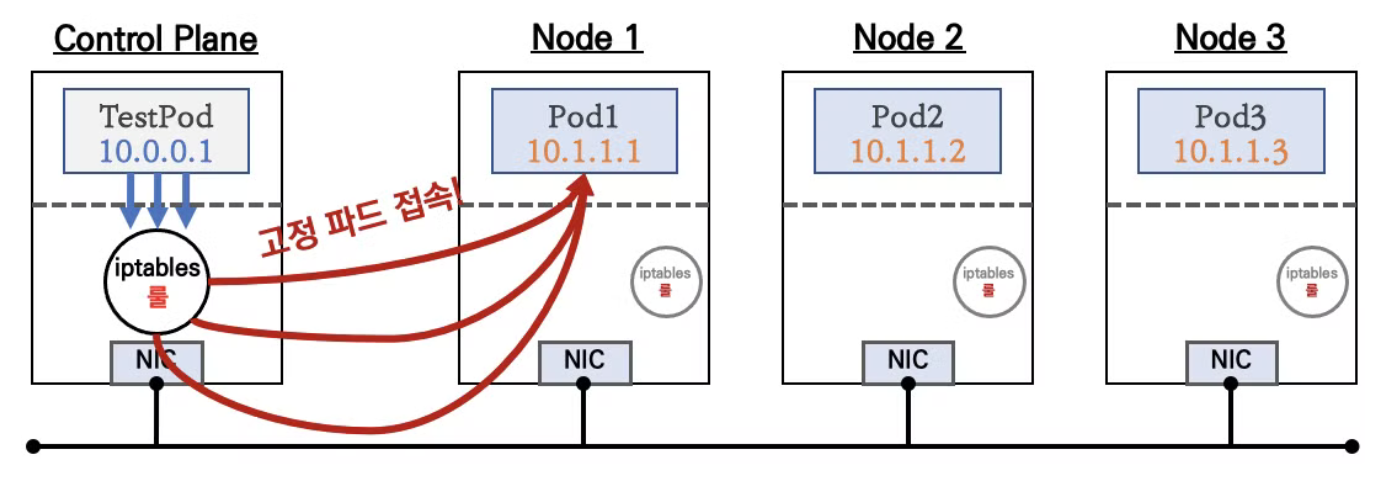
Tips) Pod 간 통신 흐름

- 위 그림에서 TestPod가 다른 노드에 있는 Pod1로 트래픽을 보낼 때 이미 TestPod가 존재하는 노드의 iptables에 의해 대상 노드에 있는 Pod로 패킷을 보내도록 NAT가 됨. 이런 이유로 워커 노드의 eth0 네트워크 인터페이스에 tcpdump를 떠봐도 Service의 Ip:port로는 패킷이 전송되지 않음
- iptables에 의해 패킷이 NAT 될 때 Service에 연결된 Pod가 여러개라면 랜덤한 Pod가 선택됨
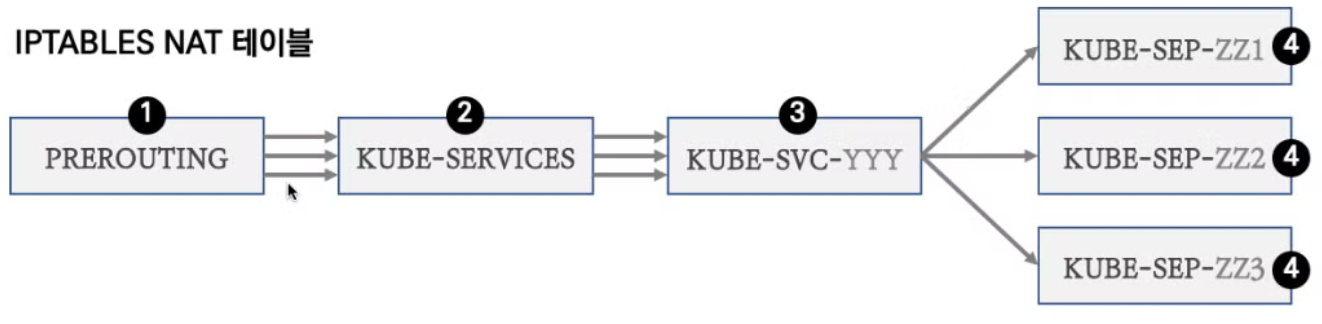
- 워커노드의 대상 Pod로 전송된 패킷은 처리 후 반환 될 때 패킷을 받을 노드와 Pod의 IP:port를 알아야하는 하는데 이 정보는 conntrack 테이블에 기록되어 있음
Tips) Endpoint Slice란?
- iptables를 사용하는 경우 Pod 수가 많아질 수록 iptables rule을 갱신하는데 엄청난 부하가 생길 수 있음
- kube-proxy의 iptables 설정에서 minSyncPeriod 값을 조정할 수가 있는데 기본값은 1초임. 이는 1초마다 iptables rule과 netfilter 간 sync하는 프로세스를 수행한다는 의미인데 iptables 규칙 수가 많으면 계속해서 지연이 발생할 수 있음
- minSyncPeriod 값을 늘리면 동기화하는 텀이 늘어나기 때문에 그만큼 부하가 줄어들 수 있지만 너무 크기 잡으면 Service 변경이 동기화되지 않아서 문제가 발생할 수도 있음
- 이 때 Endpoint Slice는 iptables 규칙 반영을 부분적으로 할 수 있어서 변경된 부분에 대해서만 반영하여 성능을 향상시킬 수 있음
NodePort
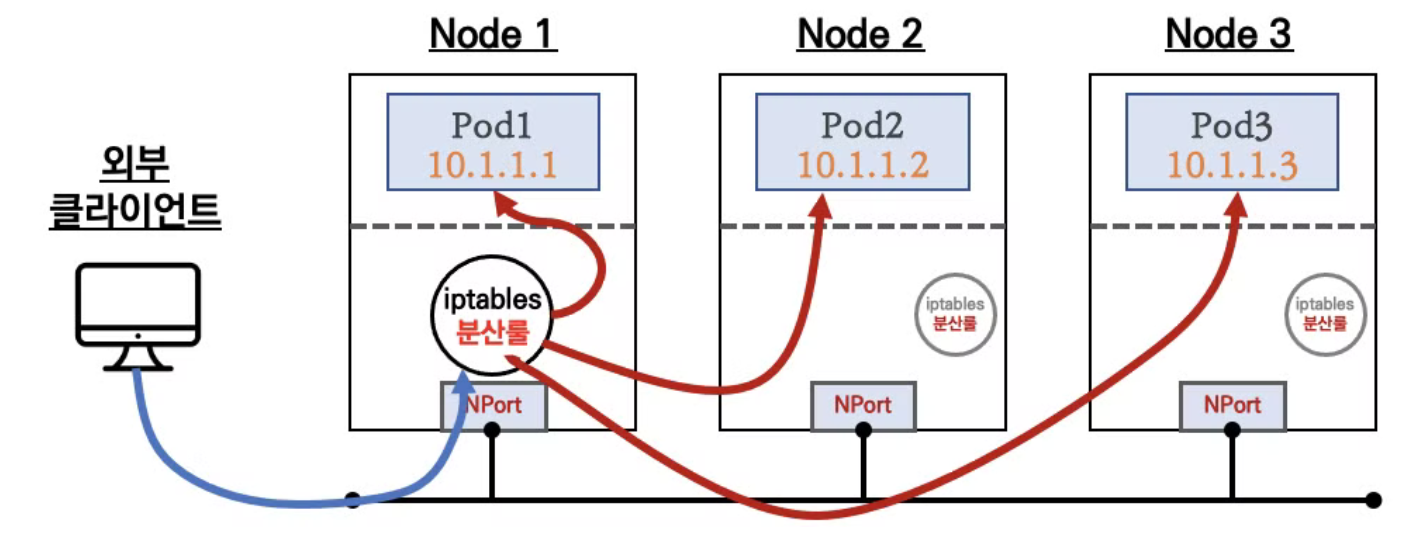
- ClusterIP가 클러스터 내부에서만 통신이 가능하다는 단점을 해결하기 위해 NodePort를 사용. 노드의 IP:Port를 통해 트래픽을 수신하는데 이 때 모든 노드의 포트가 오픈되고, Service 정보가 변경되면 kube-proxy에 의해 모든 노드의 iptables가 수정됨
- 외부 클라이언트가 노드의 IP를 알고 있다는 가정 하에 해당 노드에 오픈된 IP와 Port로 트래픽을 전달하면 해당 노드가 iptable Rule을 통해 대상 Pod에 트래픽을 전달함
- 이런 이유로 어떤 노드로 트래픽이 가더라도 목적지 Pod로 트래픽이 전송 됨
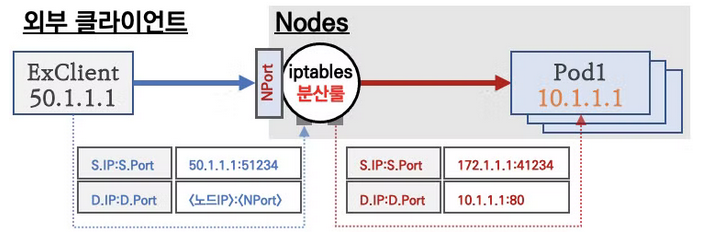
- 외부 클라이언트가 NodePort로 오픈된 워커노드에 트래픽을 보내면 출발지 IP가 해당 워커노드의 IP로 SNAT 되고, 노드 내에서는 대상 Pod로 트래픽을 전달하기 위해 iptables rule에 의해 목적지 IP 주소가 Pod의 IP로 변경(DNAT) 됨
- 이 때 만약 로깅을 위해 클라이언트의 IP를 보존하려면 기본적으로는 불가능하고 ExternalTrafficPolicy나 X-Forwarded-For와 같은 방식을 사용해야함
- Pod에서 처리 후 응답하면 다시 해당 워커 노드로 응답이 반환되고 워커 노드를 통해 외부 클라이언트에 응답하게 됨
LoadBalancer
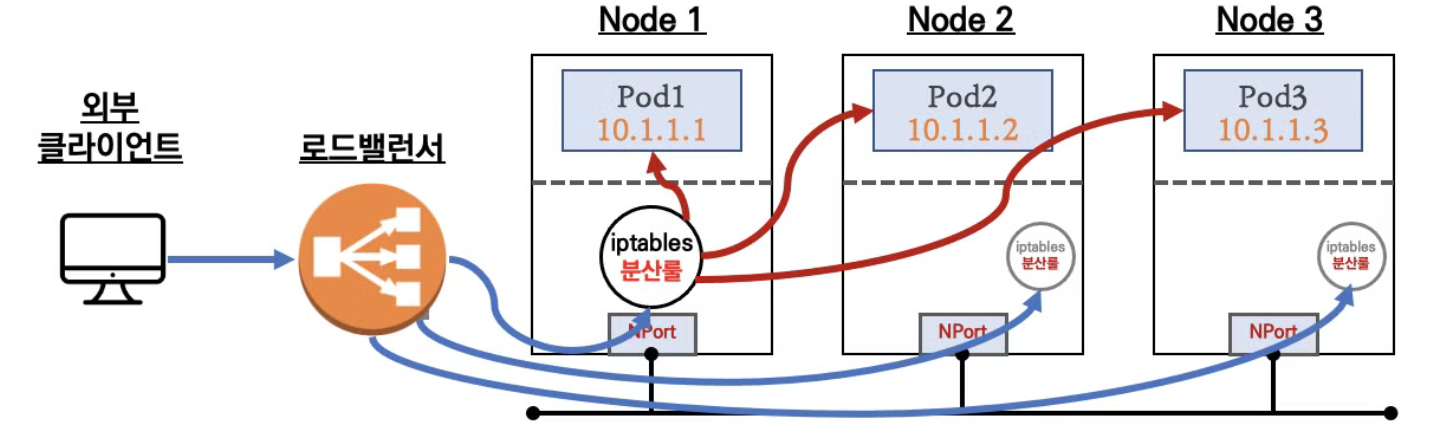
- AWS/Azure/GCP와 같은 CSP의 매니지드 서비스로 제공되는 로드밸런서를 사용할 수 있음
- 로드밸런서에서 NodePort를 통해 노드에 트래픽을 전달할 수 있도 있고, direct로 Pod로 전달할 수도 있음
- 온프레미스 환경에서는 Citrix, F5 전통적인 L7 벤더들이 제공하는 장비 기반이나 비용이 저렴한 LoxiLB와 같은 솔루션을 사용할 수 있음
세션 어피티니
- 기본적으로 서비스를 생성하면 대상 Pod들로 랜덤 부하분산이 되는데 클라이언트 요청을 매번 동일한 목적지 Pod로 전달하기 위해서 사용

- 위 그림과 같이 Session Affinity 설정이 None이면 기본적으로 iptables rule을 통해 랜덤 부하분산 됨
- ClientIP로 설정하면 처음 연결된 Pod로 계속해서 통신함 (TTL 있음)
- kubectl patch svc svc-clusterip -p '{"spec":{"sessionAffinity":"ClientIP"}}'

- 위 그림과 같이 클라이언트의 1000번 요청이 전부 동일 Pod로 전송됨
- 이 동작은 결국 iptables의 설정 변경으로 이루어짐

- 세션 어피니티를 설정하면 위 그림에서 원래 iptables에 없던 설정인 -m recent --rcheck --seconds 10800이라는 것이 추가됨
- -m recent는 recent 모듈을 사용해서 최근에 요청된 IP 주소를 추적하고 관리하고, --rcheck 옵션으로 패킷의 소스 주소가 현재 리스트에 있는지 확인함. 그리고나서 --seconds 10800 옵션으로 지정된 시간(초) 내에 요청한 주소가 리스트에 있었는지를 확인하고, 있을 경우 동일한 목적지로 연결함. (기본 3시간 동안 유지)