"병렬 프로세싱에 있어서 은밀히 나타날 수 있는 메모리 거짓 공유가 무엇인가?"
메모리 거짓 공유는 버그나 오류는 아니지만 프로그램 성능에 큰 영향을 미칠 수 있는 문제입니다.
따라서 똑같은 기능의 프로그램을 작성하더라도 메모리 거짓 공유를 어느 정도 고려한 것과 그렇지 않은 것은 프로그램의 질에 큰 차이가 나타날 수 있습니다.
일종의 최적화와 동일한 테마일 수도 있겠네요.
일단 먼저 간단히 캐시라인에 대해서 알아봅시다.
단일 프로세싱에서 다음과 같은 두 코드가 있다고 하죠.
코드1
|
int temp[1000][1000]; for( int i = 0; i < 1000; ++i ) { for( int j = 0; j < 1000; ++j ) { temp[ i ][ j ] = i * j; // 인덱싱 i, j } } |
코드2
|
int temp[1000][1000]; for( int i = 0; i < 1000; ++i ) { for( int j = 0; j < 1000; ++j ) { temp[ j ][ i ] = i * j; //인덱싱 j, i } } |
딱히 설명을 하지 않아도 될 코드입니다만, 두 코드의 차이점은 바로 인덱싱 방법에 있습니다.
다음 코드가 어느 메모리 스택 공간에 적재된다고 합시다. temp 배열은 다음과 같이 되겠지요.
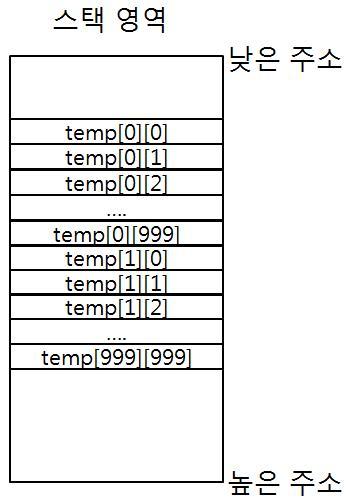
그리고 각 루프문에서 배열의 요소에 접근을 하겠지요.
그 전에 캐시 메모리에 대해서 들어보셨을 겁니다.
일반적인 펜티엄 프로세서인 경우 L1, L2캐시가 존재하는데 캐시 메모리는 CPU내부에 존재하여 주 메모리보다 접근성이 뛰어나 훨씬 빠른 속도를 제공할 수가 있다는 것입니다.
그래서 접근이 빈번히 일어날 만한 데이터를 주 메모리에서 캐시 메모리에 적재하여 주 메모리가 아닌 캐시메모리를 참고할 수가 있습니다. (물론 위의 과정은 프로세서 차원에서 해줍니다)
따라서, 루프문에서 a 배열을 접근할 때 이 배열을 가용한 캐시 라인에 적재를 하는데 (프로세서에 따라 다를 수 있겠지만 64kbyte 정도라고 가정하겠습니다. 즉, 16개의 temp요소가 캐시라인에 적재가 되지요.)
코드 1 의 경우는,
a[0][0]에 접근할 때 a[0][15]까지의 데이터가 하나의 캐시라인에 적재하게 되고 a[0][15]까지는 주 메모리 접근할 필요없이 캐시에 접근하여 데이터를 쓰게 됩니다. 그리고 a[0][15]까지의 루프문이 지나면 이 64바이트의 캐시 메모리의 데이터를 주 메모리에 다시 갱신(flush) 해주게 되며 다시 a[0][16] 부터 a[0]][32]까지의 데이터를 주 메모리에서 캐시 메모리로 적재하게 됩니다.
반면 코드 2의 경우는,
똑같이 주 메모리에서 a[0][0]부터 a[0][15]까지의 데이터를 하나의 캐시라인에 적재하게 되지만, 두번째 반복 시, 코드 상 a[0][1]에 접근하는게 아니라, a[1][0]에 접근하게 되므로, 바로 캐시 라인의 데이터를 주 메모리에 갱신해 주고 다시 a[1][0]부터 a[1][15]까지의 데이터를 캐시 메모리에 적재하게 됩니다.
코드 1에 비해 코드 2가 확실히 비효율적인 작업과정을 갖으며 캐시메모리의 특성도 잘 활용하지도 못하고 있죠. (그러니 배열은 항상 코드1과 같이 접근하시길... )
메모리 거짓 공유는 이것에 대한 한 단계 발전된 상황에서 살펴볼 수 있습니다. 바로 병렬 프로세싱에서 나타날 수 있는 문제이지요. 다음과 같이 두 스레드가 동시에 가동된다고 가정합시다. (메모리 거짓 공유를 위해 일부로 가정한 상황입니다.)
|
//스레드 1 int a[1000]; int b[1000]; //스레드 1에서 가동 중인 코드 while( true ) { a[ 998 ] = i * 1000; } |
//스레드 2 int a[1000]; //스레드 1의 배열과 공유하는 배열 int b[1000]; //스레드 1의 배열과 공유하는 배열 //스레드 2에서 가동 중인 코드 while( true ) { b[ 0 ] = i ; } |
자 캐시 라인의 이용 과정을 알아봤으니,
스레드 1의 경우는 a[998]에 데이터를 삽입하기 위해서, a[998] 부터 64바이트의 데이터 즉, b[13]까지의 데이터가 어느 캐시 라인에 적재 되겠지요. (이 캐시라인을 A 캐시 라인이라고 합시다.)
물론 코드 1에서는 b의 배열의 요소는 사용하지 않습니다.
그런데, 스레드2는 b의 배열을 사용하고 있습니다.
스레드 2의 경우, 루프가 가동되어 b[0]에 접근하는 경우 b[0]부터 b[15] 까지의 데이터가 또 다른 캐시 라인에 적재되겠지요. (이 캐시라인은 B 캐시 라인이라고 합시다.)
그런데 동시에 가동되고 있던 스레드1 때문에 b[0]부터 b[13]까지의 데이터가 이미 A 캐시 라인에 적재되어 있습니다.
프로세서 차원에서는 b[0]의 데이터가 이미 캐시라인 A로부터 데이터가 변경되었을 수도 있다고 생각합니다. 따라서 B캐시 라인에 적재하기 전에 A 캐시라인으로부터 a[998]부터 b[13]까지의 데이터를 주 메모리로 갱신(flush) 해줘야 합니다. 그리고 나선 갱신된 이후의 데이터 b[0]~b[15]까지의 데이터를 B캐시 라인에 적재하지요.
역으로,
스레드 1에서 a[998]에 데이터를 삽입하려고 하는데, 스레드2에서 이미 b[0]부터 데이터가 B캐시 라인에 적재되어 있으니, B캐시 라인의 데이터를 주 메모리로 플러쉬 한 후, a[998]부터 b[13]까지의 데이터를 A캐시 라인에 적재하게 됩니다.
각 스레드 입장에서는 캐시라인의 데이터를 주 메모리로 갱신해주지 않아도 전혀 문제되지 않을 코드인데, 프로세서 차원에서는 거기까지의 사실을 알지못하고 일단 무조건 갱신한다는 게 바로 문제이지요. 따라서 쓸데없는 작업 과정으로 인한 작업 효과가 매우 비효율적임을 알 수 있습니다.
바로 이 개념이 메모리 거짓 공유(Memory False Sharing) 입니다.
애초에 거짓 공유가 일어나지 않도록 각 스레드가 참고하는 메모리의 위치를 충분히 떨어뜨려 놓도록 설계를 해야하겠지요. 아니면 tbb(Threading Building Blocks - cache_aligned_allocator<T>)와 같이 어느정도 메모리 거짓 공유를 해결해주는 병렬 처리 라이브러리를 활용하는 것도 좋은 방안이 되겠습니다. 하지만, 아직까지 어떤 메커니즘이라도 위의 문제를 완벽히 해결해 주지는 못할 것입니다.
자, 다음은 거짓 공유로 인한 성능 차이를 테스트 한 결과 및 샘플 코드 입니다.
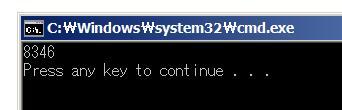
거짓 공유 발생 시
|
int b[100000]; //메모리 위치 0x010AABC8 ~ 0x0110C644 UINT WINAPI Thread1( LPVOID p ) { //거짓 공유가 발생하도록 b와 충분히 접근 인덱스 번호를 가까이 놓았습니다. UINT WINAPI Thread2( LPVOID p ) {
HANDLE hThread = ( HANDLE ) _beginthreadex( NULL, 0, Thread1, (void*) a, NULL, NULL ); WaitForSingleObject( hThread, INFINITE ); CloseHandle( hThread ); DWORD end = GetTickCount(); cout << end - start << endl; } |
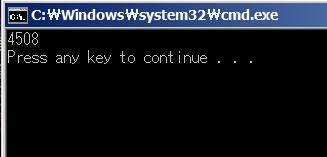
거짓 공유 미 발생 시
|
int b[100000]; //메모리 위치 0x010AABC8 ~ 0x0110C644 UINT WINAPI Thread1( LPVOID p ) { //거짓 공유가 발생하지 않도록 b와 충분히 접근 인덱스 번호를 떨어뜨려 놓았습니다. UINT WINAPI Thread2( LPVOID p ) {
HANDLE hThread = ( HANDLE ) _beginthreadex( NULL, 0, Thread1, (void*) a, NULL, NULL ); WaitForSingleObject( hThread, INFINITE ); CloseHandle( hThread ); DWORD end = GetTickCount(); cout << end - start << endl; } |
간단한 작업임에도 불구하고 성능이 2배 가량 차이나네요.
어쨌든 메모리 거짓 공유에 대한 개념 설명은 여기까지 입니다. 앞으로 병렬프로세싱 구현에 있어서 고려하시길 바라며
이상 마치겠습니다
[출처] 메모리 거짓 공유 ( Memory False Sharing )|작성자 Hermet
'Education > Bit 18th' 카테고리의 다른 글
| [MSSQL] 서버 인증 모드 변경 by MSDN (0) | 2012.12.20 |
|---|---|
| 멀티 쓰레드 프로그래밍이 어려운 까닭 by 펌글 (0) | 2012.12.10 |
| 함수 객체 #2 (0) | 2010.12.09 |
| 함수 객체 #1 (0) | 2010.12.09 |
| 비트 수료식 소감문 (0) | 2010.03.15 |

댓글