데이터베이스(MySQL)
개발 환경에서는 서버에 Mysql을 docker로 구동하여 사용하고 있는데, 대규모 트래픽을 감당하기 위해서는 이 데이터베이스 서버 또한 replica를 구성하거나 백업 관리 및 성능을 위한 튜닝을 해야하는 등의 관리 요소가 증가하게 됩니다. 더구나 데이터베이스는 서비스에 있어서 가장 중요한 부분이기 때문에 작은 실수도 서비스에 큰 영향을 끼칠 수가 있습니다. 그래서 이러한 위험성과 서버팀 3명이서 모든 것을 관리해야하기 때문에 이러한 위험성을 줄이고 관리 요소도 줄이기 위해 AWS의 데이터베이스 서비스를 사용하기로 결정하였습니다. 그 중에서도 Aurora를 선택하게 되었는데, Aurora는 현재 RDS 서비스 중 가장 가파른 성장세를 보이고 있고, 사용자들이 점차 증가하고 있다는 점과 내부적으로 AWS의 여러 서비스를 사용함으로써 기존의 MySQL만으로 해낼 수 없었던 여러가지 긍정적인 효과(예를 들어 스토리지로 S3를 사용하여 빠른 속도로 replica와 동기화를 맞추고, 여러 가용영역에 복제되는 S3의 특성으로 인한 내구성 또한 가질 수 있음)로 인한 높은 성능을 내고 있다는 점으로 인해 선택하게 되었습니다.

Aurora를 비롯한 Amazon RDS를 활용하게 되면 데이터베이스의 버전을 항상 최신으로 유지할 수 있도록 자동으로 패치되고, 백업이나 장애로부터의 복구 등이 자동으로 수행되기 때문에 개발자가 관리에 신경쓰지 않아도 되는 이점이 있습니다. 적은 인원으로 인프라를 관리하려면 이러한 관리 요소는 최대한 줄이는 것이 좋다고 판단을 하였고, EC2 인스턴스에 비해서 관리 비용을 추가로 지불해야하지만 직접 관리를 함으로써 소비되는 인력에 대한 비용이나 머신 비용을 생각한다면 이러한 관리형 서비스를 이용하는 것이 더 효과적이라고 생각하였습니다.
다행히 개발 중에 겪었던 이슈였는데, Amazon RDS의 데이터베이스 엔진에 대한 업그레이드 스케쥴 설정을 자동으로 할 경우 업그레이드로 인해 데이터베이스가 중단될 수 있습니다. 업그레이드에 대한 부분은 점검 시 필요에 따라 수동으로 수행함으로써 의도치 않은 데이터베이스 종료를 방지하였습니다.
Amazon RDS의 인스턴스는 외부에 노출될 필요가 없고, EC2 인스턴스에서만접근이 가능하면 되기 때문에 Private Subnet에 생성하고 Security Group 설정을 통해 웹 서버와 관리를 위한 Bastion 서버가 속한 Security Group에서만 접근이 가능하도록 설정합니다.
Multi-AZ 구성
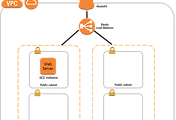
AWS는 여러개의 Data Center들의 클러스터로 이루어진 AZ(Availability Zone)과 이 AZ들로 이루어진 Region 단위로 서비스가 제공됩니다. 각 AZ들은 장애에 대해 서로 영향을 받지 않도록 독립된 구조로 설계되어 있습니다.그러므로 서버를 구성할 때 여러 AZ로 확장될 수 있는 구조로 구성하는 것이 더 안정적입니다. 참고로 AWS에서는 장애가 발생한 경우 SLA에 의해 서비스 이용 요금의 일부를 크레딧으로 제공해주는 계약 내용이 존재합니다. 이 때, 하나의 AZ로만서비스를 구성한 경우에는 장애가 발생하더라도 SLA 정책에 포함되지 않기 때문에 이러한 보상을 받을수가 없습니다.
하나의 Availability Zone에만 웹 서버 기능을 하는 EC2 인스턴스와 데이터베이스를 둘 경우에는 AZ에 장애 발생하게 된다면 서비스가 중단될 수밖에 없습니다. 동일한 환경을 다른 AZ에 구성하면 하나의 AZ에 장애가 발생하더라도 서비스는 계속해서 유지할 수 있게 됩니다.

EC2 인스턴스를 다른 AZ에 복제할 때 AMI(Amazon Machine Image)를 사용하면 편리합니다. AMI는 해당 EC2 인스턴스의 환경 그대로 저장하기 때문에 손쉽게 다른 AZ로 동일한 환경의 EC2인스턴스를 생성할 수 있습니다.
위 그림과 같이 Multi-AZ를 적용하고, 사용자에게 단일 경로를 통해 웹 서버에접속이 가능하게 하려면 각 AZ로의 트래픽 분산 할 수 있도록 ELB사용이 필수적입니다. ELB는 현재 ClassicLoad Balancer와 Application Load Balancer 그리고 Network Load Balancer를 사용할 수가 있는데 ALB를사용하는 경우에는 Layer 7을 이용하는 로드밸런서 이기 때문에 도메인이나 HTTP Header 정보를 통해 더욱 유연한 로드 밸런싱이 가능하고, WAF(Web Application Firewall) 적용이 가능하기 때문에 보안을 강화할 수 있는 이점이 있습니다. 개선해야 할 웹 서버는 연결지향적인 요소나 HTTP 헤더를 이용하는기능이 요구되지 않기 때문에 Classic Load Balancer가 적합하다고 판단하였습니다.
ELB는 트래픽을 분배할 EC2 인스턴스에 주기적인 헬스 체크를 통해 정상 여부를 판단합니다. 만약 연결된 EC2 인스턴스가 비정상인 경우에는 로드밸런싱 리스트에서 제외시켜서 정상적인 EC2 인스턴스로만 트래픽을 전달하여 서비스에 문제가 발생하지 않도록 합니다. RDS의 경우 Multi-AZ 기능을 활성화 하는 것만으로 다른 AZ에 Stanby 데이터베이스를 생성하여 고가용성을 확보할 수 있습니다.
서비스를 런칭하기 전에 모집했던 사전 가입에서 50만명정도의 고객들이 신청을 해주었기 때문에 초반에 굉장히 많은 트래픽이 몰릴 것으로 예상하고 AWS에 ELB 프리워밍 신청을 하였습니다. 티켓 발행에 있어서 몇 번 실수를 해서 AWS 담당자분께 도움을 받아 무사히 프리워밍을 신청할 수 있었습니다. 그래서 처음 2대가 가동되어 있던 ELB 머신이 8대로 증가한 것을 확인할 수 있었습니다. 트래픽이 줄어들어 8대까지 불필요해지는 경우에는 일주일 정도 유지되다가 자동으로 축소됩니다.
데이터베이스의 부하 분산
오토 스케일링을통해 EC2 인스턴스의 수가 증가될 수록 이에 연결된 단일 데이터베이스인 Amazon RDS로의 쿼리량 또한 점점 증가하게 됩니다. RDS가 관리형 서비스이긴 하지만 확장에 대한 설정 없이는 한정된 머신 리소스를 사용하기 때문에 모든 처리량을 감당해낼 수는 없습니다. 이를 위해 Read Replica를 분리하여 하나의 데이터베이스에서 처리하던 것을 분산하여 처리를 할 수 있습니다.

Aurora는 Read Replica 사용시 MySQL처럼 binLog를 전달하여 동일한 쿼리를 Read Replica에서도 수행하는 로그 재생 방식이 아닌 마스터와 Replica가 공유하는 스토리지를 사용함으로써 로그 재생이 필요 없기 때문에 즉각적인 동기화가 가능합니다. 또한 내부적으로 비동기식 처리와 캐시 사용, 여러 AZ간 데이터 복제 등 빠른 성능과 안정성을 위한 처리가 이루어지고 있습니다.이러한 성능을 내면서도 저렴한 비용으로 이용할 수 있는 이유는 서비스 중심의 아키텍처를 적용한 클라우드 환경이기 때문입니다. 즉, 내부적으로 DynamoDB, S3, Route 53 등의 다른 AWS 서비스들과 유기적으로 연결되어 있습니다. 백업을 위해 S3를 사용하여 연속, 증분 백업을 하기 때문에 빠르고 안전하게 데이터를 보관할 수 있습니다.
자주 사용되는 데이터와 이벤트 성 데이터의 경우에는 ElasticCache(Redis)를 활용하였습니다. 개발 초기에는 데이터베이스의 부하를 생각하여 고객의 모든 데이터를 데이터베이스와 병행하여 Redis에도 동일하게 저장한 후 1차 적으로 Redis에서 데이터를 가져오고 갱신이 일어날 경우 데이터베이스와 동기를 맞추는 방식을 사용하였었습니다. 하지만 데이터 이중화로 인해서 개발 생산성도 떨어지고, 심적으로 데이터를 불신하게 되는 것을 느끼고 이중화를 제거하였고, 자주 사용되지만 유실되더라도 고객에게 이득으로 돌아가는 데이터들만 Redis에 저장하는 방식으로 방향을 전환하였습니다.
로그성 데이터의 경우에는 읽기보다 쓰기가 더 빈번하게 발생하기 때문에 초기에 DynamoDB를 사용했었습니다. 하지만 로그 데이터를 통해 통계를 내고 집계를 해야하는 부분들이 존재해서 결과적으로는 Amazon Elasticsearch Service로 변경하였습니다. 로그 데이터 수집에 대한 부분은 추후 포스팅에서 다루도록 하겠습니다.
참고
- AWS 백서 - Amazon RDS
- AWS 백서 - ELB
- AWS 백서 - ElastiCache
- Amazon Aurora 성능 향상 및 마이그레이션 모범 사례 - 구승모 솔루션즈 아키텍트(AWS 코리아), 김충희 시니어 리서처(SEWORKS)
같이 보면 좋은 포스팅
하이브 런칭기 #6 - 부하테스트
하이브 런칭기 #7 - 로그 관리 및 지표/통계
'Work > 개발 노트' 카테고리의 다른 글
| 하이브 런칭기 #5 - 웹서버 관리는 Beanstalk에게 (0) | 2018.08.15 |
|---|---|
| 하이브 런칭기 #4 - 오토스케일링 및 알림 설정 (0) | 2018.08.15 |
| 하이브 런칭기 #2 - AWS 기본 구성 (0) | 2018.08.15 |
| 하이브 런칭기 #1 - 사내 환경 구성 (0) | 2018.08.15 |
| jenkins build history cleanup (0) | 2017.05.22 |


댓글