관찰 가능성(Observability)의 개념
- 관찰 가능성이란 외부의 신호와 특성(시그널링)을 통해 내부 애플리케이션의 상태를 이해하고 추론할 수 있게 하는 시스템 특성
- 시스템의 외부에서 내부 상태를 파악할 수 있는 능력을 의미
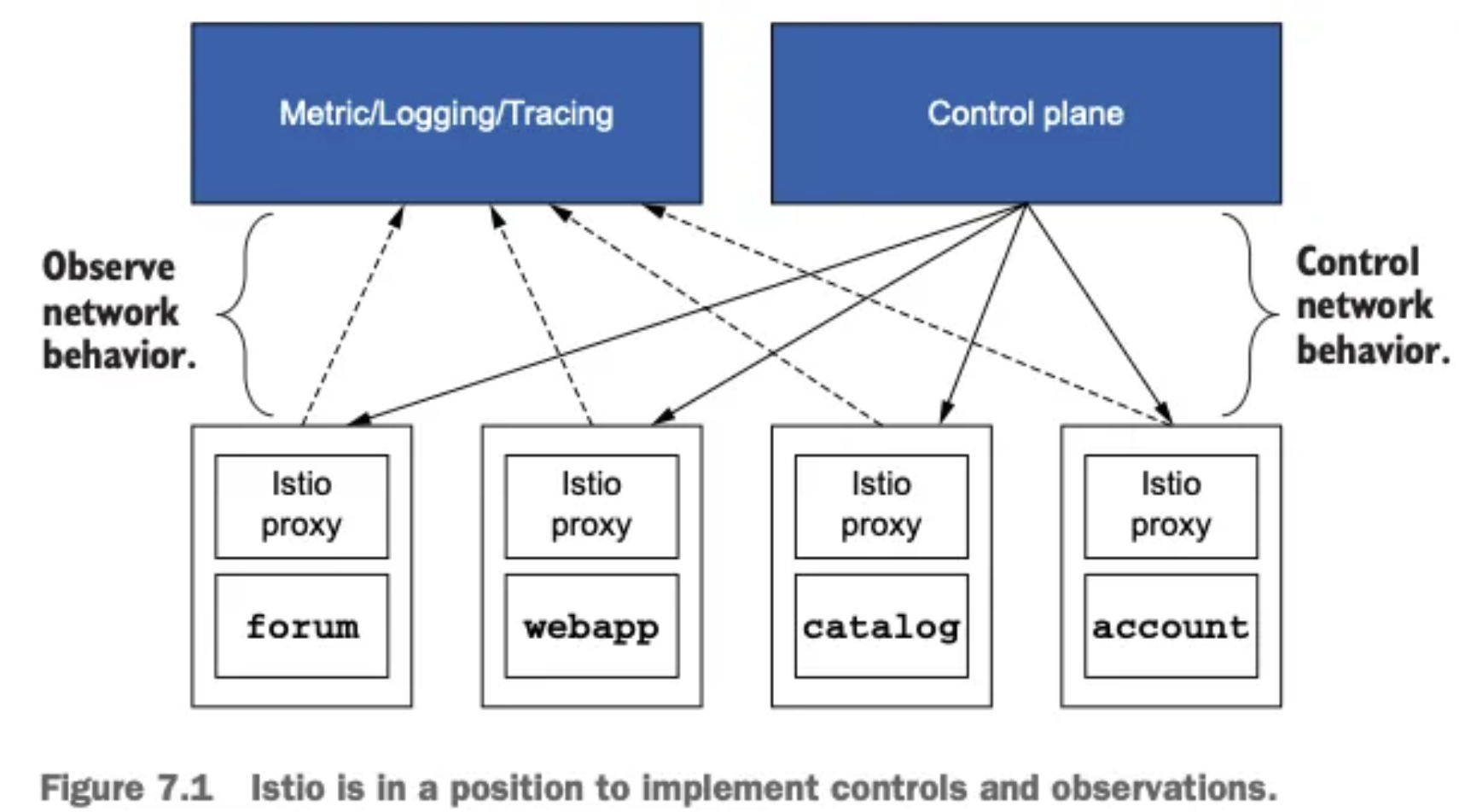
Istio의 관찰 가능성 기능은 마이크로서비스 아키텍처의 복잡성을 관리하는 데 큰 도움을 주며, 데이터 플레인과 컨트롤 플레인에서 제공하는 다양한 메트릭을 통해 시스템 상태를 효과적으로 모니터링하고, 장애 발생 시 신속하게 대응할 수 있음. 특히 Istio는 서비스 간 통신을 중간에서 처리하기 때문에, 애플리케이션 수준의 메트릭을 효과적으로 수집할 수 있는 이상적인 위치에 있어 관찰 가능성 구현에 매우 적합함
모니터링과의 차이
- 모니터링: 시스템의 특정 상태와 메트릭을 추적하고 알림을 제공하는 것에 중점
- 관찰 가능성: 모니터링을 포함한 더 넓은 개념으로, 시스템 동작의 이해와 문제 해결에 초점
마이크로서비스 환경에서의 중요성
- 온프레미스 레거시 환경의 단일 서비스가 마이크로서비스로 분리되면서(예: 하나의 서버가 20개 마이크로서비스로 나뉨) 시스템 복잡성이 크게 증가함
- 이러한 복잡한 환경에서 장애 발생 시 빠른 복구를 위해서는 관찰 가능성을 제공하는 도구와 계측 기법이 필수적
Istio의 데이터 플레인 메트릭
표준 Istio 메트릭
Envoy 프록시(데이터 플레인)가 기본으로 제공하는 메트릭으로, 기본 활성화되어 있음
| 메트릭명 | 설명 |
| istio_requests_total | 총 요청 수 카운터 |
| istio_request_duration_milliseconds | 요청 처리 소요 시간 |
| istio_request_bytes | 요청 크기 |
| istio_response_bytes | 응답 크기 |
| istio_grpc_* | gRPC 관련 메트릭 |
- 이 메트릭들은 TCP, HTTP, HTTPS, gRPC 프로토콜에 대해 제공됨
확장 Envoy 메트릭
표준 메트릭 외에도 Envoy는 추가적인 상세 메트릭을 제공하며 기본적으로 비활성화되어 있음
- 커넥션 활성 상태: cluster.*.upstream_cx_active
- HTTP 응답 코드: http.*.downstream_rq_2xx
- 내부/외부 트래픽 구분:
- 내부 트래픽: cluster.internalcluster.example.com
- 외부 트래픽: 인그레스 게이트웨이를 통한 요청
- SSL/TLS 정보:
- 사용 중인 암호화 알고리즘: ssl.cipher.*
- TLS 핸드쉐이크 카운트: ssl.handshake
- TLS 버전: 예) TLS 1.3
- 로드 밸런싱 정보: cluster.*.lb_*
- 클러스터 엔드포인트 정보: 리전, 존, 가중치 등
활성화 방법
1. Istio Operator 명세에서 설정 (메시 전체 적용)
spec:
meshConfig:
proxyStatsMatcher:
inclusionPrefixes:
- "http"
- "cluster"
2. 워크로드별 애노테이션 설정 (특정 워크로드만 적용)
metadata:
annotations:
proxy.istio.io/config: |-
proxyStatsMatcher:
inclusionPrefixes:
- "http"
- "cluster"
3. Telemetry API 사용 (가장 유연한 방법, 최신 권장 방식)
- 원하는 워크로드나 네임스페이스에 대해 선택적으로 메트릭, 로그, 트레이스 설정 가능
주의사항 : 확장 메트릭을 활성화하면 많은 양의 데이터가 생성되어 시스템에 과부하를 줄 수 있으므로, 신중하게 필요한 메트릭만 선택적으로 활성화하는 것이 바람직함
Istio의 컨트롤 플레인 메트릭
istiod가 제공하는 메트릭
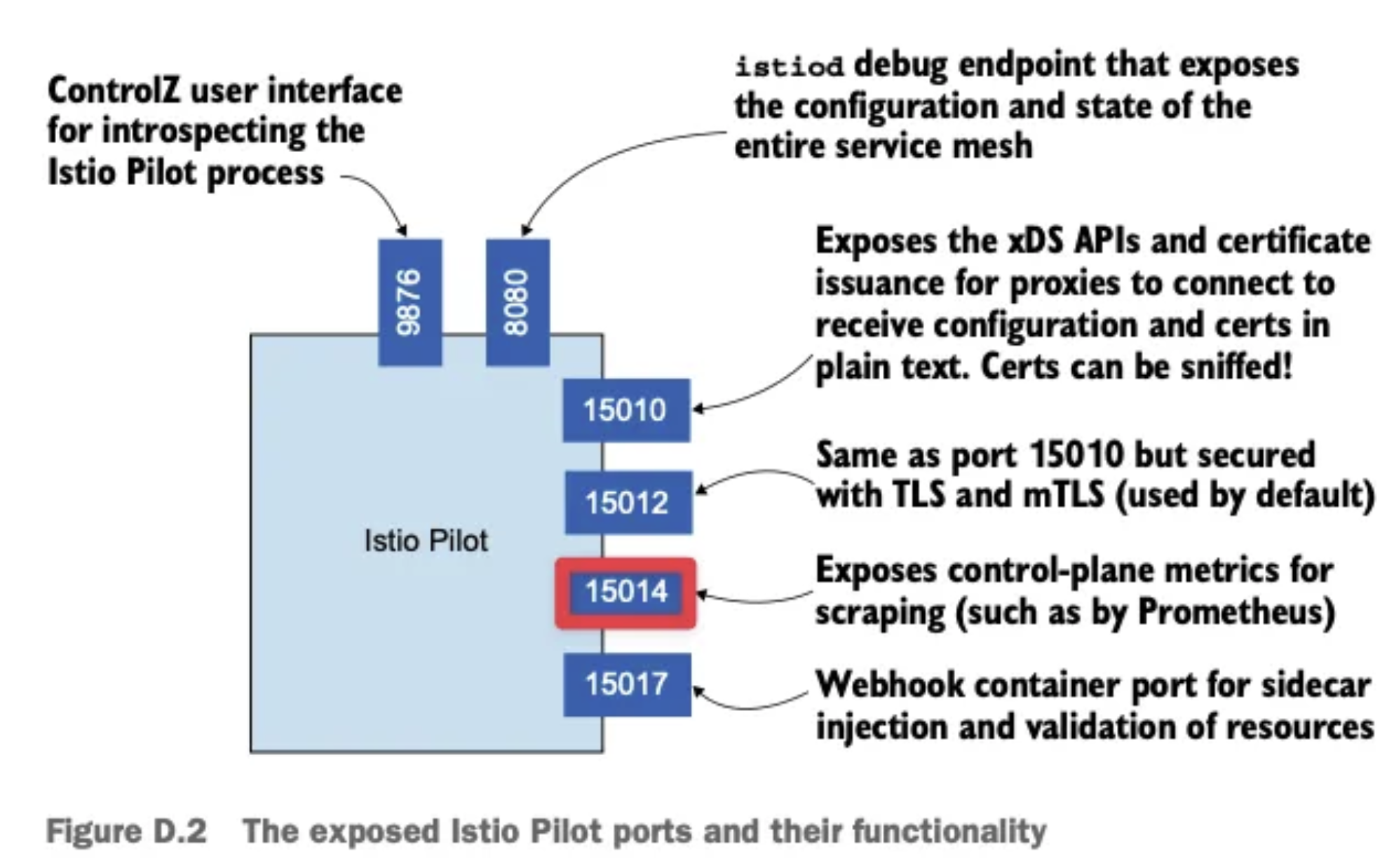
컨트롤 플레인(istiod)은 15014 포트를 통해 메트릭을 제공함
| 리스닝 포트 | 설명 |
| 8079, 8080 | API 서비스 포트 |
| 15014 | 메트릭 제공 포트 |
| 15017 | 검증 웹훅 포트 |
| 15010, 15011, 15012 | XDS, CA 서비스 포트 |
주요 컨트롤 플레인 메트릭 카테고리
- 설정 동기화 메트릭
- pilot_proxy_convergence_time: 데이터 플레인 프록시에 설정 주입 시간 분포
- 0.1초 이내 동기화된 건수
- 0.5초 이내 동기화된 건수
- 1초 이내 동기화된 건수
- 3초 이내 동기화된 건수
- pilot_proxy_convergence_time: 데이터 플레인 프록시에 설정 주입 시간 분포
- 서비스 및 리소스 관련 메트릭
- pilot_services: 컨트롤 플레인이 알고 있는 Kubernetes 서비스 개수
- pilot_virtual_services: 사용자가 설정한 VirtualService 개수
- pilot_xds_cds_reject: 잘못된 CDS 설정 개수
- 인증서 관련 메트릭
- citadel_server_csr_count: CSR(Certificate Signing Request) 요청 횟수
- citadel_server_success_cert_issuance_count: 성공적으로 발급된 인증서 수
- XDS API 업데이트 관련 메트릭
- pilot_xds_pushes: 각 XDS 유형별 업데이트 횟수
- CDS(Cluster Discovery Service)
- EDS(Endpoint Discovery Service)
- LDS(Listener Discovery Service)
- RDS(Route Discovery Service)
- pilot_xds_pushes: 각 XDS 유형별 업데이트 횟수
- 버전 정보
- istio_build: Istio 컴포넌트 버전 정보 (예: pilot=1.17.8)
메트릭 접근 및 수집 방법
직접 메트릭 접근 방법
# 표준 컨테이너 이미지 사용 시
kubectl exec [pod-name] -c istio-proxy -- curl localhost:15000/stats
# Distroless 이미지 사용 시 (curl이 없는 경우)
kubectl exec [pod-name] -c istio-proxy -- pilot-agent request GET stats- 다양한 엔드포인트:
- /stats: 모든 통계
- /stats/prometheus: Prometheus 형식 통계
- /clusters: 클러스터 정보
- /listeners: 리스너 정보
메트릭 수집 및 시각화 도구
- Prometheus: 메트릭 수집 및 저장
- Grafana: 메트릭 시각화 및 대시보드
- Kiali: Istio 특화 시각화 도구로, 메트릭 및 트레이스 정보를 통합 시각화
Prometheus 개요
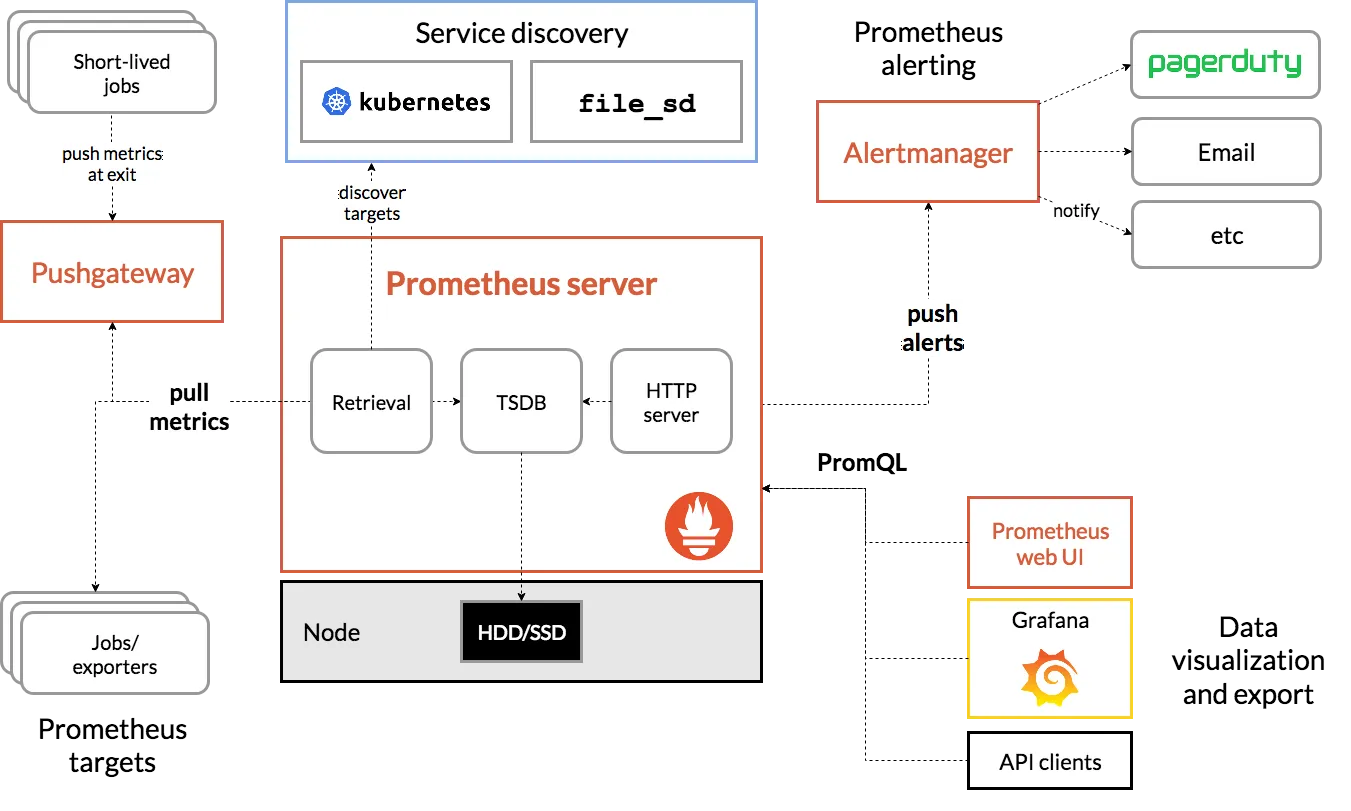
- Prometheus는 오픈소스 시스템 모니터링 및 경고 도구로, 메트릭 수집 엔진과 모니터링 및 알림 도구의 집합
- 2016년 CNCF(Cloud Native Computing Foundation)에 두 번째 프로젝트로 가입했으며, 현재 Kubernetes 생태계에서 가장 널리 사용되는 모니터링 솔루션
Prometheus의 작동 방식
Prometheus는 Pull 방식으로 작동하며, 이는 Zabbix와 같은 다른 모니터링 도구가 사용하는 Push 방식과는 다름
- Pull 방식(Prometheus): Prometheus 서버가 모니터링 대상에 직접 접근하여 메트릭을 가져옴
- Push 방식(Zabbix): 모니터링 대상이 모니터링 서버에 메트릭을 보냄
- Prometheus 서버는 설정된 간격(일반적으로 15초)마다 타겟 엔드포인트에서 메트릭을 스크래핑(scraping)함
- 이를 위해 모니터링 대상은 HTTP 엔드포인트를 노출시켜야 함
Istio와 메트릭 수집 아키텍처
Istio 서비스 프록시(Envoy)는 다음 포트를 통해 메트릭을 제공
- 15090 포트: Envoy가 제공하는 기본 메트릭 엔드포인트
- 15020 포트: 다음 세 가지 역할 수행
- 메트릭 집계 및 노출(aggregating & exposing metrics)
- DNS 프록시 기능
- 엔드포인트 탐지와 파일럿 에이전트 역할
제공되는 메트릭은 다음과 같이 확인 가능
# 15090 포트의 메트릭 확인
curl http://<pod-ip>:15090/stats/prometheus
# 15020 포트의 메트릭 확인
curl http://<pod-ip>:15020/metricsIstio 메트릭의 구성요소
- 메트릭 유형:
- 카운터(Counter): 누적되는 값으로, 항상 증가 (예: 요청 총 개수)
- 게이지(Gauge): 현재 상태를 나타내는 값으로, 증가하거나 감소 가능 (예: 현재 활성 연결 수)
- 히스토그램/디스트리뷰션(Histogram/Distribution): 값의 분포를 나타냄 (예: 응답 시간 분포)
- 메트릭 방향:
- 인바운드(Inbound): 서비스로 들어오는 트래픽
- 아웃바운드(Outbound): 서비스에서 나가는 트래픽
- 디멘션(Dimension): 메트릭에 대한 속성
- 리포터(reporter): 메트릭을 제공한 Istio 프록시 (source, destination)
- 소스 앱(source_app): 호출 주체(caller)
- 대상 앱(destination_app): 호출 대상(callee)
- 응답 코드(response_code): HTTP 응답 코드 (예: 200, 500)
- 기타 속성
Prometheus 설치 및 구성
kube-prometheus 스택 설치
# Helm 리포지토리 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# kube-prometheus-stack 설치
helm install prometheus prometheus-community/kube-prometheus-stack -f values.yaml -f custom-values.yaml
kube-prometheus 스택을 사용하여 Prometheus를 설치할 때 포함되는 구성요소들:
- Prometheus 서버
- Grafana
- AlertManager
- 다양한 Exporter
- Prometheus Operator: Prometheus 인스턴스 관리
Prometheus Operator와 CRD
Prometheus Operator는 다음과 같은 CRD(Custom Resource Definition)를 제공
- Prometheus: Prometheus 서버 인스턴스 정의
- ServiceMonitor: 서비스 기반 메트릭 수집 대상 정의
- PodMonitor: 파드 기반 메트릭 수집 대상 정의
- AlertManager: 알림 관리자 정의
- PrometheusRule: 알림 규칙 정의
Prometheus Operator가 실제 Prometheus 서버를 배포하는 방식은 다음과 같음
- CRD를 통해 Prometheus 리소스 배포
- Prometheus Operator가 해당 리소스 감지
- Operator가 정의된 설정에 따라 Prometheus 서버 파드 배포
Istio 메트릭 수집 구성
Istio 컨트롤 플레인 메트릭 수집
Istio 컨트롤 플레인(istiod) 메트릭을 수집하기 위해 ServiceMonitor 사용
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: istio-component-monitor
namespace: monitoring
spec:
selector:
matchLabels:
istio: pilot
namespaceSelector:
matchNames:
- istio-system
endpoints:
- port: http-monitoring # 실제로는 15014 포트
interval: 15s- istio: pilot 레이블이 있는 서비스를 선택하고, http-monitoring 포트(15014)에서 메트릭을 스크래핑함
Istio 데이터 플레인 메트릭 수집
Istio 데이터 플레인(Envoy 사이드카 프록시) 메트릭을 수집하기 위해 PodMonitor 사용
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: envoy-stats-monitor
namespace: monitoring
spec:
selector:
matchExpressions:
- {key: sidecar.istio.io/status, operator: Exists}
podMetricsEndpoints:
- path: /stats/prometheus
port: 15090
interval: 15s
relabelings:
- action: keep
sourceLabels: [__meta_kubernetes_pod_container_name]
regex: "istio-proxy"
- action: keep
sourceLabels: [__meta_kubernetes_pod_annotationpresent_prometheus_io_scrape]PodMonitor는 파드 레벨에서 메트릭을 수집하며, ServiceMonitor는 서비스 레벨에서 수집함
- ServiceMonitor: 서비스가 있는 워크로드(Deployment, StatefulSet 등)
- PodMonitor: 서비스 없이 직접 파드에 액세스해야 하는 경우(DaemonSet 등)
Istio 표준 메트릭
- istio_requests_total: 총 요청 수 (카운터)
- istio_request_duration_milliseconds: 요청 처리 시간 (디스트리뷰션)
- istio_request_bytes: 요청 바이트 크기 (디스트리뷰션)
- istio_response_bytes: 응답 바이트 크기 (디스트리뷰션)
- istio_tcp_connections_opened_total: 열린 TCP 연결 수 (카운터)
- istio_tcp_connections_closed_total: 닫힌 TCP 연결 수 (카운터)
- istio_tcp_sent_bytes_total: 보낸 TCP 바이트 수 (카운터)
- istio_tcp_received_bytes_total: 받은 TCP 바이트 수 (카운터)
Telemetry API
최근 Istio는 EnvoyFilter 대신 더 간단하고 효율적인 Telemetry API를 제공하며, 이를 통해 특정 네임스페이스나 워크로드에 대해서만 메트릭 설정을 변경할 수 있음
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: mesh-default
namespace: istio-system
spec:
metrics:
- providers:
- name: prometheus
overrides:
- match:
metric: REQUEST_COUNT
tagOverrides:
source_cluster:
value: "downstream_peer.cluster_id"Istio metric 커스터마이징
새로운 메트릭 생성하기
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
values:
telemetry:
v2:
prometheus:
configOverride:
inboundSidecar:
definitions:
get_calls:
name: "get_calls"
type: COUNTER
value: "1"
metrics:
- name: get_calls
tags_to_remove:
- destination_port
- request_protocol
outboundSidecar:
definitions:
get_calls:
name: "get_calls"
type: COUNTER
value: "1"
metrics:
- name: get_calls
tags_to_remove:
- destination_port
- request_protocol
gateway:
definitions:
get_calls:
name: "get_calls"
type: COUNTER
value: "1"
metrics:
- name: get_calls
tags_to_remove:
- destination_port
- request_protocol- 타입: COUNTER - 요청 개수를 누적하여 기록하는 카운터 타입
- 값: 1 - 요청마다 1씩 증가
- 적용 범위: inboundSidecar, outboundSidecar, gateway 모두에 적용
- 제거할 태그: destination_port, request_protocol - 이 태그들은 메트릭에서 제외
📝 메트릭 유형: 메트릭 타입으로는 COUNTER, GAUGE, HISTOGRAM 등이 있습니다. COUNTER는 계속 증가하는 값, GAUGE는 현재 상태를 나타내는 값, HISTOGRAM은 값의 분포를 표현합니다.
# 새 메트릭 적용 및 확인
kubectl apply -f new-metric.yaml
# 적용된 메트릭 확인
kubectl -n istio-system get cm istio -o yaml | grep -A 20 "get_calls"- Prometheus에서는 istio_get_calls라는 이름으로 조회됨
- istio_ 접두어는 설정에서 자동으로 추가되도록 설정되어 있음
메트릭 정보 전달을 위한 파드 구성
새로 정의한 메트릭을 Sidecar에서 인식하도록 웹앱 디플로이먼트에 다음 설정을 추가
apiVersion: apps/v1
kind: Deployment
metadata:
name: webapp
spec:
template:
metadata:
annotations:
sidecar.istio.io/statsInclusionPrefixes: "get_calls"- 웹앱 파드 재시작 후 트래픽이 발생하면 새로운 메트릭을 확인할 수 있음
- Prometheus 메트릭 그래프를 통해 시간에 따른 HTTP 요청 개수의 증가 추세를 볼 수 있음
속성(Attribute) 생성 및 활용
- 특정 API 호출이나 경로만 추적하기 위해 새로운 속성을 정의하고 활용할 수 있음
EnvoyFilter를 통한 속성 정의
아래 예제에서 istio_operation_id라는 새 속성을 만들어 카탈로그 서비스의 /items API에 대한 GET 호출만 특별히 추적함. Envoy의 WebAssembly 플러그인인 AttributeGen 플러그인을 사용하여 속성을 생성
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: attribute-gen-example
namespace: istio-system
spec:
configPatches:
- applyTo: HTTP_FILTER
match:
context: SIDECAR_OUTBOUND
proxy:
proxyVersion: '^1\.17.*'
listener:
filterChain:
filter:
name: "envoy.filters.network.http_connection_manager"
subFilter:
name: "envoy.filters.http.router"
patch:
operation: INSERT_BEFORE
value:
name: istio.attributegen
typed_config:
"@type": type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.wasm.v3.Wasm
value:
config:
configuration:
"@type": "type.googleapis.com/google.protobuf.StringValue"
value: |
{
"attributes": [
{
"output_attribute": "istio_operation_id",
"match": [
{
"value": "get_items",
"condition": "request.url_path == '/items' && request.method == 'GET'"
},
{
"value": "create_items",
"condition": "request.url_path == '/items' && request.method == 'POST'"
},
{
"value": "delete_items",
"condition": "request.url_path == '/items' && request.method == 'DELETE'"
}
]
}
]
}
vm_config:
vm_id: attributegen
runtime: envoy.wasm.runtime.null
code:
local: { inline_string: "envoy.wasm.attributegen" }- istio_operation_id라는 새로운 속성을 정의
- 요청 경로와 HTTP 메서드에 따라 다른 값을 할당함
- /items에 GET 요청 → get_items
- /items에 POST 요청 → create_items
- /items에 DELETE 요청 → delete_items
속성을 메트릭에 활용하기 위한 설정
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
values:
telemetry:
v2:
prometheus:
configOverride:
outboundSidecar:
dimensions:
upstream_operation: istio_operation_id- upstream_operation이라는 새 디멘션을 정의하고, 앞서 생성한 istio_operation_id 속성의 값을 할당
설정 적용 및 확인
kubectl apply -f envoy-filter.yaml kubectl apply -f operation-dimension.yaml
적용 후 Prometheus에서 확인
# 새로 추가된 차원으로 필터링
istio_request_duration_milliseconds{upstream_operation!=""}- upstream_operation 값이 존재하는 요청(즉, 우리가 정의한 특정 경로와 메서드에 대한 요청)만 필터링함
메트릭 시각화
Prometheus는 기본적인 쿼리와 그래프 기능은 제공하지만, 시각화 측면에서는 제한적이기 때문에 다음과 같은 도구를 활용하여 메트릭을 더 효과적으로 시각화할 수 있음
- Grafana: 다양한 대시보드와 시각화 옵션을 제공
- Kiali: 서비스 그래프와 트래픽 흐름을 시각적으로 표현
Istio 관찰성의 중요성
Istio의 관찰성 기능은 개발자가 명시적으로 코드를 작성하지 않아도 다음과 같은 "골든 시그널" 메트릭을 제공
- 성공률 (Success Rate)
- 실패율 (Error Rate)
- 지연시간 (Latency)
- 트래픽량 (Traffic Volume)
- 리소스 사용률 (Resource Utilization)
Grafana를 통한 Istio 메트릭 시각화
- Grafana는 시계열 데이터 시각화를 위한 오픈소스 플랫폼으로, Istio 환경에서 수집된 메트릭을 효과적으로 시각화하는 데 사용됨
- Grafana 자체는 데이터를 저장하지 않고, Prometheus와 같은 외부 데이터 소스에서 데이터를 가져와 시각화
Grafana 설정
데이터 소스 설정
Grafana에서 Prometheus를 데이터 소스로 연결하는 방법:
- Grafana 좌측 메뉴의 Configuration(톱니바퀴) > Data Sources 선택
- Prometheus 데이터 소스가 이미 설정되어 있는지 확인
- 일반적으로 prometheus:9090과 같은 서비스 이름과 포트로 설정됨
대시보드 설정
Istio 대시보드를 Grafana에 추가하는 방법:
1. ConfigMap을 통한 대시보드 설정
# istio in action 8장의 예제 코드 apply 후 ConfigMap에 라벨 추가
kubectl label configmap istio-grafana-dashboards grafana_dashboard=1 -n istio-system
2. 대시보드 확인
- Grafana에서 대시보드 메뉴로 이동하면 Istio 대시보드들이 추가됨
- 주요 대시보드: Control Plane, Mesh, Performance, Service, Workload
Control Plane 메트릭
Control Plane 대시보드는 아래의 Istio의 컨트롤 플레인 구성 요소에 대한 메트릭을 시각화함:
- istiod 버전 정보
- 메모리 및 CPU 사용량
- 디스크 사용량
- Envoy 프록시로의 설정 푸시 관련 메트릭(CDS, EDS, LDS, RDS)
- 고루틴(goroutine) 개수
- 오류 정보
- 설정 동기화 정보
- 활성 연결 개수
Prometheus 쿼리 예시:
sum(istio_build{component="server"})
- Grafana에서 패널의 쿼리를 확인하려면 패널 클릭 후 "Explore" 버튼을 선택하여 Prometheus 쿼리 확인 가능
Data Plane 메트릭
Data Plane 메트릭은 주로 Service 대시보드에서 확인할 수 있으며, 다음과 같은 정보를 포함:
- 클라이언트 요청 볼륨(RPS)
- 성공률 및 오류율
- 응답 시간(latency)
- HTTP 상태 코드 분포
- 클라이언트 및 서버 워크로드 정보
주요 쿼리 예시:
sum(irate(istio_requests_total{reporter="destination",destination_service=~"$service",response_code!~"5.*"}[1m])) / sum(irate(istio_requests_total{reporter="destination",destination_service=~"$service"}[1m]))
- 특정 서비스의 성공률(non-5xx 응답 비율)을 계산
분산 트레이싱 (Distributed Tracing)
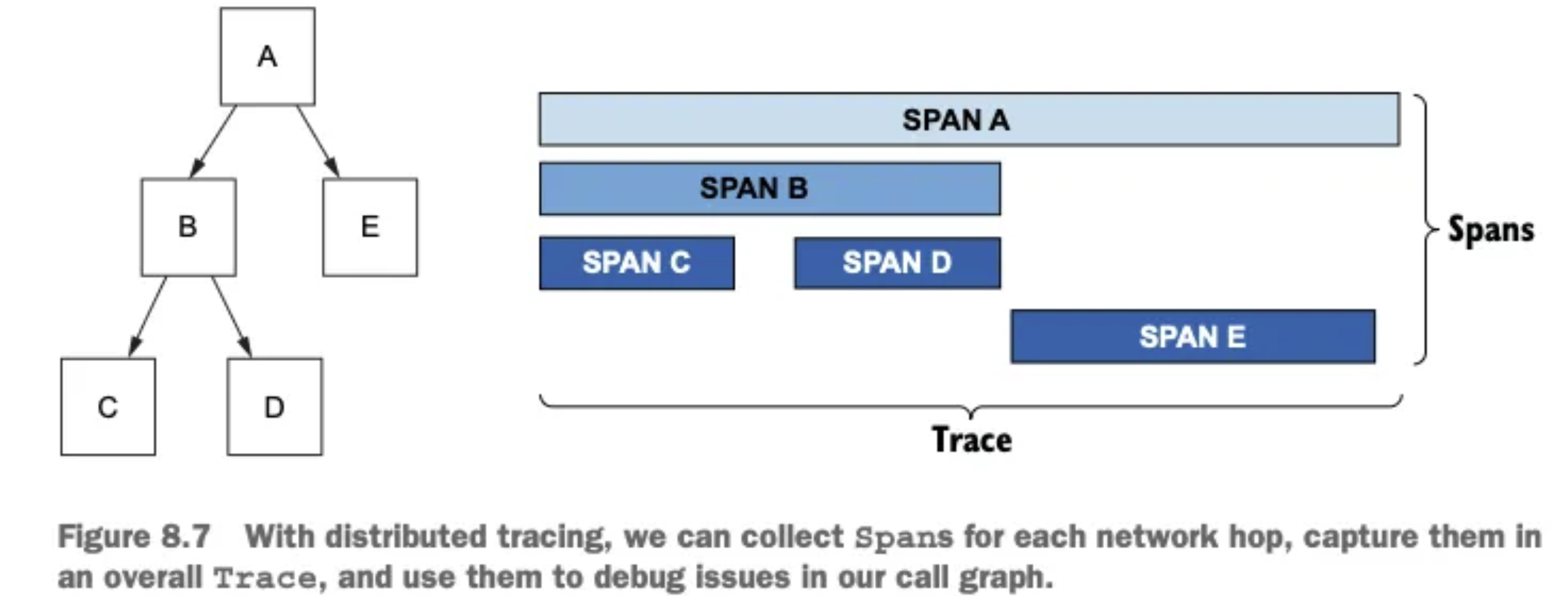
- 분산 트레이싱은 마이크로서비스 환경에서 요청의 전체 경로를 추적하는 기술
- 2010년 Google이 Dapper라는 논문을 통해 소개한 개념으로, 요청에 주석을 붙여 서비스 간 호출을 상관관계화하고 호출 그래프를 생성함
주요 개념:
- 스팬(Span): 서비스나 구성 요소의 작업 단위를 나타내는 데이터
- 트레이스(Trace): 여러 스팬의 집합으로, 하나의 요청 전체 흐름을 표현
- 트레이스 컨텍스트(Trace Context): 서비스 간에 전파되는 트레이스 정보
- 전파(Propagation): 트레이스 컨텍스트가 서비스 간에 전달되는 과정
OpenTelemetry와의 관계
- OpenTelemetry는 오픈 트레이싱(OpenTracing)을 포함한 더 넓은 텔레메트리 프레임워크
- 현재 OpenTracing은 아카이브되었으며, OpenTelemetry가 텔레메트리 데이터의 생성, 수집, 관리를 위한 표준 프레임워크로 사용됨
분산 트레이싱 작동 원리
- 최초 요청에 트레이싱 헤더가 없으면 새 트레이스 ID 생성
- 각 서비스는 자신이 처리하는 부분에 대해 스팬을 생성
- 트레이스 컨텍스트를 다음 서비스로 전파
- Envoy 프록시는 트레이싱 헤더를 자동으로 애플리케이션에 전달
- 애플리케이션은 트레이싱 헤더를 유지하고 전파해야 함
주요 트레이싱 헤더:
- x-request-id: 요청 식별자
- x-b3-traceid: 트레이스 식별자
- x-b3-spanid: 현재 스팬 식별자
- x-b3-parentspanid: 부모 스팬 식별자
Jaeger를 이용한 분산 트레이싱 설정
Jaeger 설치:
kubectl apply -f jaeger.yaml
kubectl expose deployment jaeger --type=NodePort --port=16686 --target-port=16686 --name=jaeger-nodeport
트레이싱 샘플링 설정:
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
meshConfig:
defaultConfig:
tracing:
sampling: 100.0 # 100% 샘플링
트레이싱 고급 기능
x-envoy-force-trace 헤더를 true로 설정하여 특정 요청을 강제로 트레이싱:
curl -H "x-envoy-force-trace: true" http://example.com
Envoy에서 트레이스에 커스텀 태그 추가:
apiVersion: networking.istio.io/v1beta1
kind: Telemetry
metadata:
name: tracing-custom
spec:
tracing:
- customTags:
custom:
literal:
value: "test-tag-value"세 가지 유형의 커스텀 태그:
- 명시적 값 (literal)
- 환경 변수 (environment)
- 요청 헤더 (header)
Envoy 프록시의 트레이싱 백엔드 변경:
apiVersion: v1
kind: Pod
metadata:
name: webapp
annotations:
proxy.istio.io/config: |
tracing:
zipkin:
address: not-zipkin:9411트레이싱 사용 시 주의사항
- 개발자는 트레이스 컨텍스트를 애플리케이션 간에 전파해야 함
- 운영 환경에서는 샘플링 비율을 적절히 설정해야 함(보통 10% 정도)
- 트레이싱은 시스템에 부하를 줄 수 있으므로 성능 영향 고려 필요
Kiali를 통한 서비스 메시 시각화
- Kiali는 Istio 서비스 메시를 위한 전용 관측 콘솔로, 서비스 간 통신 상황을 실시간으로 시각적으로 표현
- 트러블슈팅, 시각적 검증, 모니터링에 유용함
Kiali 설치
Kiali Operator를 통한 설치 권장:
# Kiali Operator 설치
helm repo add kiali https://kiali.org/helm-charts
helm install kiali-operator kiali/kiali-operator
# Kiali CR 생성
kubectl apply -f - <<EOF
apiVersion: kiali.io/v1alpha1
kind: Kiali
metadata:
name: kiali
spec:
auth:
strategy: anonymous
external_services:
prometheus:
url: http://prometheus:9090
tracing:
enabled: true
in_cluster_url: http://jaeger-query:16686
use_grpc: true
EOF
NodePort로 Kiali 노출:
kubectl expose deployment kiali --type=NodePort --port=20001 --target-port=20001 --name=kiali-nodeport3.3 Kiali 주요 기능
Overview
- 네임스페이스별 애플리케이션 및 서비스 상태
- 라벨 및 기본 정보 표시
Graph
- 서비스 간 통신 흐름을 실시간 그래프로 표시
- 트래픽 방향, 볼륨, 성공/오류율 시각화
- 필터링 및 그룹화 옵션
Workloads
- 워크로드 세부 정보 및 상태
- 트래픽, 로그, 인바운드/아웃바운드 지표
- 트레이스 정보와 통합된 뷰
Services
- 서비스 세부 정보 및 상태
- 서비스 엔드포인트 및 워크로드 매핑
- 트래픽 라우팅 규칙 확인
Istio Config
- Istio 구성 검증 및 문제 식별
- VirtualService, DestinationRule 등의 구성 확인
Kiali와 분산 트레이싱 통합
Kiali는 아래의 방법으로 Jaeger의 트레이스 정보를 통합하여 보여줌:
- 워크로드 뷰에서 트레이스 탭 선택
- 트레이스 세부 정보 및 스팬 정보 확인
- 호출 경로 시각화
'Work > 개발 노트' 카테고리의 다른 글
| [Istio 스터디] 2주차 - Envoy, Istio Gateway (0) | 2025.04.19 |
|---|---|
| [Istio 스터디] 1주차 - Istio 소개, 첫걸음 (0) | 2025.04.12 |
| [KANS] 8주차 - Cilium CNI (0) | 2024.10.26 |
| [KANS] 6주차 - Ingress, Gateway API (0) | 2024.10.13 |
| [KANS] 5주차 - LoadBalancer(MetalLB, IPVS) (0) | 2024.10.06 |




댓글