이번 주차 스터디에서 다룰 내용 :
- 데이터 플레인 관련 문제 확인 및 처리 방법
- 워크로드 설정 오류 시 원인 파악 과정과 절차
- 로그, 텔레메트리(Telemetry) 등의 확인 기법
- Istiod 컨트롤 플레인 파드 최적화
- 성능 최적화를 위한 방법들
실습 시 주의 사항 :
- 11장에서는 컨트롤 플레인 튜닝 실습을 위해 약 200개 이상의 더미 서비스를 생성해야 하는데, 초기에 서비스 IP를 24비트로 설정하면 IP가 고갈되는 문제 있을 수 있음
- 이를 해결하기 위해 CIDR를 22비트로 변경하여 약 1,000개 정도의 IP를 사용할 수 있도록 수정 필요
데이터 플레인 트러블슈팅
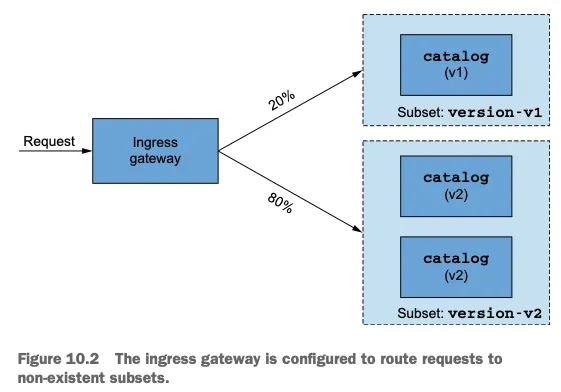
- Istio API를 통해 설정을 하게 되면(예: VirtualService나 DestinationRule 선언), Istiod가 이를 Envoy 설정으로 변환하여 istio-proxy에 주입하고 최신 설정이 적용됨
- 트러블슈팅 실습을 위한 목표 구성:
- Ingress에 들어오는 트래픽 중 20%는 카탈로그 버전 1로, 80%는 카탈로그 버전 2로 라우팅
- 가중치 기반 분산을 위해서는 '서브셋'(subset, 부분집합)이라는 개념을 사용하여 서비스를 구성해야함
- 카탈로그 버전 2는 파드 복제본이 2개임
- 현재 문제는 DestinationRule CRD API 리소스를 생성하지 않아 요청이 실패하고 있음
- Ingress에 들어오는 트래픽 중 20%는 카탈로그 버전 1로, 80%는 카탈로그 버전 2로 라우팅
- 실습 환경 단순화를 위해 웹 앱은 배포하지 않고, Ingress 게이트웨이에서 바로 카탈로그 서비스로 요청이 전달되도록 구성
문제 확인 및 트러블슈팅
- 서비스에 접근을 시도하면 "503 Service Unavailable" 에러가 발생함
- 일반적으로 데이터 플레인의 문제일 가능성이 높음
- 데이터 플레인에 문제가 발생했을 때 권장되는 첫 번째 접근법은 컨트롤 플레인에서 원인을 빠르게 배제하는 것
- 컨트롤 플레인에서 문제가 있으면 당연히 데이터 플레인에도 문제가 있기 때문에 컨트롤 플레인에서 데이터 플레인과 연관된 문제가 없는지 먼저 확인
- 데이터 플레인의 최신 상태는 일관성을 가지는데, 이는 "Eventually Consistent"(결과적 일관성)임.
- 컨트롤 플레인과 동기화가 되어야만 데이터 플레인에 반영이 되고, 이는 약간의 시간차가 있을 수 있음
- Istio 컨트롤 플레인은 Kubernetes API를 통해 서비스와 엔드포인트 정보를 가져옴
- 만약 노드에 문제가 있어 헬스 체크가 실패하면 그 정보가 Kubernetes API 서버에 반영되고, Istiod는 이를 감시(watch)하여 서비스나 엔드포인트 상태 정보를 업데이트
문제 발생 시 이벤트 순서:
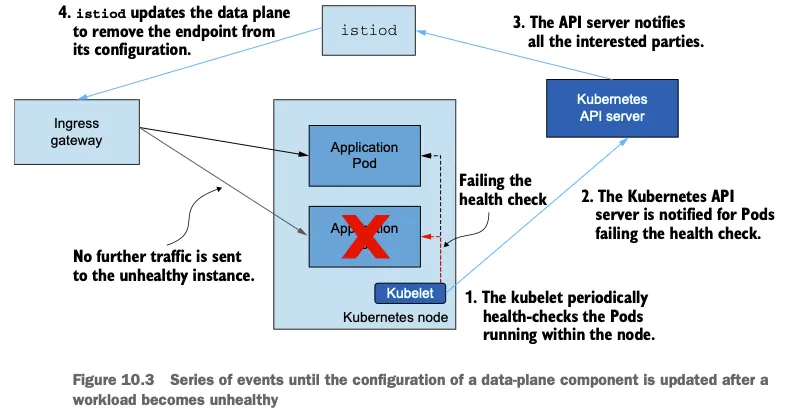
- Kubelet이 프로브(probe) 설정에 따라 주기적으로 헬스 체크를 수행
- 헬스 체크에 문제가 발생하면 그 변경 사항이 Kubernetes API 서버에 반영됨
- Istiod가 이를 감시하여 상태 정보를 업데이트
- 건강하지 않은 인스턴스로 더 이상 트래픽을 전송하지 않도록 설정
따라서 특정 서비스에서만 503 에러가 발생한다면, 해당 서비스의 사이드카 프록시(istio-proxy)의 상태를 먼저 확인하고, XDS(Cross-Domain Service) 동기화가 정상적으로 되고 있다면 컨트롤 플레인과 istio-proxy 간의 서비스 디스커버리 구성에는 문제가 없는 것으로 판단할 수 있음
Kiali를 통한 문제 확인
- 특정 워크로드에 문제가 있을 때 가장 빠르게 검증할 수 있는 방법 중 하나로 Kiali(키알리)가 있음
- Kiali 웹 인터페이스에 접속하면 오버뷰 화면에서 바로 경고(warning) 확인 가능
- 예를 들어, 카탈로그 버전 1과 2에 대해 "Configuration Warning Found"라는 메시지가 표시됨
- 이를 클릭하면 "KIA1107: Subset not found"라는 상세한 에러 코드가 나타나고, 이는 VirtualService에는 서브셋을 사용하도록 설정했지만 DestinationRule에 해당 서브셋이 선언되어 있지 않다는 의미함
- Kiali는 이러한 휴먼 에러를 직관적으로 발견할 수 있게 해주며, 각 경고 메시지에 대한 상세 설명과 해결 방법도 제공함
istioctl을 통한 설정 분석 및 진단
istioctl 명령어 툴을 사용하여 설정을 확인하고 문제를 진단할 수도 있음.
주요 서브 커맨드:
1. analyze: 설정을 분석하고 문제점을 검출
istioctl analyze -n istio-injection- 이 명령어를 실행하면 "Error [IST0101] Referenced DestinationRule not found"와 같은 에러 코드가 출력됨
2. describe: 특정 워크로드의 설정 상태를 상세히 조사
istioctl x describe pod $POD_NAME- 이 명령어는 파드의 포트, 서비스, mTLS 설정, 노출된 서비스 등의 정보를 보여주며, "no matching destination pod subset" 같은 에러 메시지도 표시함
- 이러한 도구들은 CI/CD 파이프라인에도 통합할 수 있음. 예를 들어 istioctl analyze 명령어가 에러를 반환하면 (종료 코드가 0이 아님), 파이프라인 빌드를 실패하게 할 수 있음
Envoy 관리 인터페이스
문제가 Kiali나 istioctl로 간단히 해결되지 않을 때는 Envoy의 설정을 직접 수동으로 확인해야할 수도 있음. Envoy는 운영 관리와 분석을 위한 관리 인터페이스를 제공하는데 이를 접근하려면 아래와 같이 istio-proxy 컨테이너가 있는 파드로 포트 포워딩을 설정해야함
kubectl port-forward <pod-name> 15000:15000- 웹 브라우저에서 http://localhost:15000에 접속하면 Envoy의 전체 설정, 힙 덤프, 리스너, 런타임, 통계 지표 등을 확인할 수 있음
- Envoy의 전체 설정은 매우 방대하고, 사람이 읽기 어렵게 되어 있음("People not meant" - 사람을 위한 설정이 아님)
- istioctl proxy-config와 같은 명령어를 사용하여 가독성을 높인 형태로 설정을 확인하는 것이 좋음
istioctl을 사용한 프록시 설정 쿼리
istioctl proxy-config 명령어를 사용하면 다음과 같은 Envoy 컴포넌트들의 설정을 쿼리할 수 있음:
- cluster: 업스트림 서비스들
- endpoint: 클러스터 내 실제 서비스 엔드포인트
- listener: 인바운드/아웃바운드 연결을 처리하는 리스너
- route: 요청을 어느 업스트림 클러스터로 보낼지 결정하는 규칙
- secret: 인증서 등의 보안 정보
Istio Ingress 게이트웨이의 리스너 설정 확인:
istioctl proxy-config listener istio-ingressgateway-<hash> -n istio-system
특정 포트(8080)의 라우트 설정 확인:
istioctl proxy-config route istio-ingressgateway-<hash> -n istio-system --port 8080 -o json
클러스터 설정 확인:
istioctl proxy-config cluster <pod-name> | grep "서비스명"특정 파드에 응답 지연이 발생하는 경우
- 최종적으로 설정된 엔드포인트를 확인하여 실제 파드 IP와 일치하는지 검증
- istioctl proxy-config endpoint <pod-name> -o json | jq
- 특정 서브셋에 대한 엔드포인트만 필터링하면 해당 파드가 실제로 올바른 버전을 실행하고 있는지 확인할 수 있음
- P50, P90, P99는 각각 50%, 90%, 99% 백분위수 응답 시간으로, 전체 요청 중 해당 비율의 요청이 처리되는 시간을 나타냄
- 버전 1 과 버전 2의 HTTP 요청 응답 시간(Response Time)을 확인하고, 특히 P99(99번째 백분위수, 요청 중 99%가 이 시간 내에 처리됨)를 살펴보면 전반적인 응답 상황을 가늠해볼 수 있음
- Kiali와 Grafana(그라파나)를 통해 백분위수 지표를 확인하여 레이턴시가 상승하는 구간 확인
- Istio에서 트래픽 라우팅을 제어하는 VirtualService를 설정해서 요청 제한 시간을 변경하여 특정 시간을 초과하면 연결을 끊도록 함
- 예시 : kubectl patch vs catalog -n istio-injection --type=json -p='[{"op":"add", "path":"/spec/http/0/timeout", "value":"0.5s"}]'
- 터미널에서 요청을 보면 중간중간 504 응답 코드(Upstream Request Timeout)가 발생하는 것을 볼 수 있음.
- 일부는 응답이 빠르게 오지만, 느린 파드에 요청이 갔을 경우 Istio 프록시가 연결을 끊어버리는 것
- Envoy는 Istio의 데이터 플레인을 구성하는 핵심 프록시로, 로깅 수준을 조정하여 더 상세한 정보를 얻을 수 있음
- 현재 로깅 수준 확인 : istioctl proxy-config log {pod-name} -n {namespace}
- 각각의 로그 범주(connection, http, router, filter 등)에 대한 로깅 수준(warning, info, debug 등)을 확인하고 조정할 수 있음
- 패킷 캡처를 통해 통신 흐름을 더욱 상세하게 분석해볼 수도 있음
- ksniff라는 Kubernetes용 패킷 캡처 도구도 있음
- 파드 내에서 트래픽 흐름을 보면, 애플리케이션 컨테이너가 아닌 Istio 프록시(사이드카)가 먼저 트래픽을 받고, 프록시가 애플리케이션에 요청을 전달할 때 출발지 IP를 127.0.0.6으로 변경하며 이 IP는 파드의 네트워크 네임스페이스에서 루프백 인터페이스에 매핑됨
- 캡처된 패킷 파일을 로컬로 다운로드하여 Wireshark와 같은 도구로 분석하면 효과적 (Wireshark는 네트워크 패킷 분석을 위한 강력한 도구로, 다양한 필터링과 시각화 기능을 제공함)
- Istio 환경에서 애플리케이션 트러블슈팅은 여러 계층의 분석이 필요함
- Kiali와 Istio 메시 대시보드를 통한 모니터링, 로그 분석, 상세 로깅 설정, 그리고 패킷 캡처와 분석까지 다양한 방법을 통해 문제의 원인을 파악할 수 있음
- 특히 타임아웃 관련 문제는 VirtualService 설정과 실제 네트워크 패킷 흐름을 함께 분석해야 정확한 원인을 찾을 수 있음
Envoy 텔레메트리 분석과 컨트롤 플레인 성능 최적화
Envoy는 Istio의 데이터 플레인을 구성하는 프록시로, 다양한 텔레메트리 데이터를 제공함
Grafana에서 실패한 요청 비율 찾기
- Grafana의 Istio 서비스 대시보드에서 실패한 요청 비율을 확인할 수 있음
- Istio 서비스 대시보드에서 대상 서비스를 선택하고, 리포터(Reporter)는 소스 쪽으로 설정하여 확인
- 대시보드 패널의 수치를 확인해보면 클라이언트 성공률(Client Success Rate)과 실패율을 확인할 수 있음
- 다운스트림 쪽에서 연결을 먼저 끊은 경우 응답 플래그(Response Flags)로 확인할 수 있음
- Ingress Gateway에 있는 Istio 사이드카 프록시에서는 UT(Upstream Timeout) 플래그가 나타남
- 문제가 있는 파드의 Istio 프록시에서는 DC(Downstream Connection Close) 플래그가 나타남
Prometheus를 활용한 파드 쿼리 확인
- Prometheus를 사용하여 파드별 실패율을 쿼리할 수 있음
- 특정 목적지(destination)에 요청하고 특정 서비스에 대한 내용만 필터링하는 쿼리를 생성할 수 있음
- 응답 플래그를 DC(다운스트림 커넥션 종료)로 필터링하면 해당 조건에 맞는 메트릭만 확인 가능
sum(rate(istio_requests_total{reporter="destination", destination_service="catalog.istio-injection.svc.cluster.local", response_flags="DC"}[5m])) by (pod, response_code)
위 쿼리의 구성요소:
- istio_requests_total: 총 요청 수를 나타내는 메트릭
- reporter="destination": 서버 측에서 보고한 메트릭만 필터링
- destination_service="catalog.istio-injection.svc.cluster.local": 카탈로그 서비스로만 필터링
- response_flags="DC": 다운스트림 연결 종료 응답 플래그만 필터링
- [5m]: 5분 시간 범위
- by (pod, response_code): 파드와 응답 코드로 결과 그룹화
- rate: 초당 증가율 계산
위 쿼리를 실행하면 카탈로그 버전 2의 특정 파드에서만 DC 플래그가 발생함을 확인할 수 있고, 이를 통해 어떤 파드에서 문제가 발생하는지 정확히 파악할 수 있음
컨트롤 플레인의 성능 최적화
유령 워크로드 문제
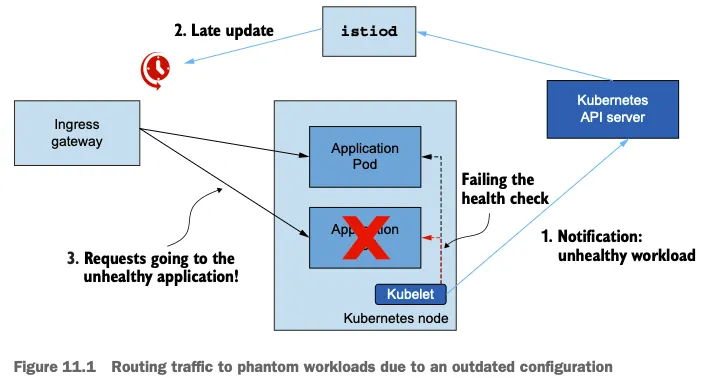
- 유령 워크로드는 Istio 컨트롤 플레인이나 Kubernetes의 성능 저하로 인해 설정 처리가 제대로 이루어지지 않을 때 발생
- 예를 들어, 특정 파드의 헬스 체크가 실패했는데 이 정보가 Istio 컨트롤 플레인에 제대로 전달되지 않으면, Istio는 여전히 그 파드를 정상적인 엔드포인트로 인식하여 트래픽을 라우팅하게 됨
- 이런 업데이트 지연으로 인해 outdated 설정이 사용되어 실제로는 존재하지 않는 엔드포인트로 요청이 전송될 수 있음
- 결국 요청 실패로 이어짐
- Istio는 데이터 일관성(eventual consistency)을 가지고 있기 때문에 어느 정도 시간이 지나면 업데이트가 이루어지고 문제가 해결되지만, 그 전까지 사용자 경험에 영향을 줄 수 있음
- 이를 방지하기 위해 헬스 체크나 아웃라이어 디텍션(outlier detection) 같은 보호 기제를 사용할 수 있음
데이터 플레인 동기화 단계 이해
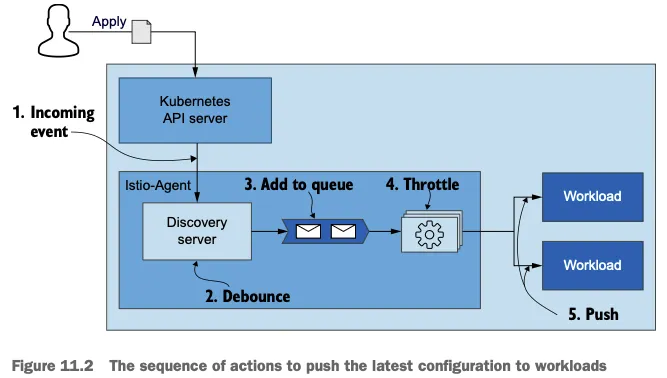
아래 다이어그램은 Kubernetes API 서버에서 발생한 이벤트가 어떻게 Istio 사이드카 프록시의 설정 변경으로 이어지는지 보여줌
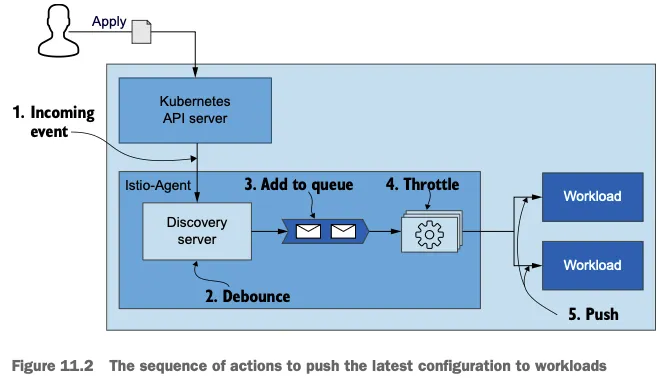
- 디바운스(Debounce): 디스커버리 서버에서 처리하는 기법으로, 짧은 시간 내에 여러 변경 이벤트가 발생할 때 이를 일정 시간 동안 모아서 한 번에 처리하는 방식입니다. 이는 불필요한 설정 업데이트 횟수를 줄여 효율성을 높임
- 푸시 큐(Push Queue): 디바운스 지연 시간이 만료되면 변경사항이 추가되는 대기열
- 스로틀링(Throttling): 동시에 처리되는 푸시 요청 개수를 제한하는 기법이며, 이를 통해 컨텍스트 스위칭과 같은 오버헤드를 줄이고 시스템 부하를 관리함
예를들어 워크로드가 500개이고 각 설정 파일이 2MB라면, 모든 워크로드 설정을 업데이트할 때 1GB의 데이터를 전송해야 하고, 이벤트가 자주 발생하면 매번 1GB 데이터를 전송하는 것은 매우 비효율적임 -> 디바운스를 사용하면 여러 이벤트를 묶어서 한 번에 처리할 수 있어 효율성이 크게 향상됨
컨트롤 플레인 성능에 영향을 주는 요소
- 변경 속도: 설정 변경이 얼마나 빠르게 발생하는지
- 할당된 리소스: CPU, 메모리 등의 할당 크기
- 워크로드 개수: 업데이트해야 할 워크로드의 수
- 설정 크기: 각 워크로드의 설정 파일 크기
컨트롤 플레인 모니터링
컨트롤 플레인 모니터링에는 구글에서 제시한 "네 가지 황금 신호"(Four Golden Signals)를 사용함 -> 지연 시간(Latency), 포화도(Saturation), 트래픽(Traffic), 오류(Error).
지연 시간 모니터링
지연 시간은 데이터 플레인을 업데이트하는 데 걸리는 시간이며 세 가지 주요 메트릭이 있음:
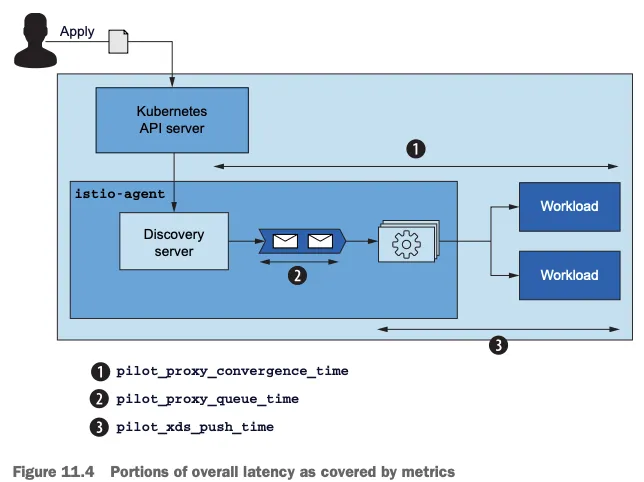
- pilot_proxy_convergence_time: 디스커버리 서버부터 워크로드까지 설정이 전달되는 전체 시간을 측정
- pilot_proxy_queue_time: 푸시 요청이 대기열에서 기다린 시간을 측정
- pilot_xds_push_time: 스로틀링 후 워크로드로 설정을 푸시하는 데 걸린 시간을 측정
Istio 컨트롤 플레인 대시보드에서 이러한 메트릭을 확인할 수 있으며, 기본적으로 "Proxy Push Time"이 표시되어 있습니다. 다른 두 메트릭은 대시보드에 추가하여 함께 모니터링할 수 있음. 대시보드를 커스터마이징하려면:
- 대시보드 편집 모드로 이동
- 기존 패널을 복제
- 복제된 패널의 이름과 쿼리를 수정(예: "Proxy Queue Time"으로 변경하고 쿼리를 pilot_proxy_queue_time_bucket으로 변경).
- 같은 방식으로 "XDS Push Time" 패널도 추가함
이렇게 세 가지 메트릭을 함께 보면 어느 단계에서 지연이 발생하는지 정확히 파악할 수 있음
포화도 모니터링
포화도는 컨트롤 플레인의 리소스 사용량을 의미하며 CPU와 메모리 사용률을 주로 확인함 (Istio 컨트롤 플레인은 주로 CPU를 많이 사용하므로 CPU 포화가 먼저 발생하는 경향이 있음)
"Resource Used" 섹션의 "CPU" 패널에서 다음 두 가지 메트릭을 확인할 수 있음
- container_cpu_usage_seconds_total: Kubernetes 컨테이너가 보고하는 CPU 사용량
- istio_build: Istio 컨트롤 플레인 파드의 CPU 사용량
이 메트릭들은 컨테이너 이름이 "discovery"인 파드(istiod)의 CPU 사용량을 보여주고, kubectl top pods 명령어로도 실시간 리소스 사용량을 확인할 수 있음
CPU 리소스 사용량은 특히 서비스 배포 시점이나 설정 업데이트가 많을 때 증가합니다. 이 경우 최적화하거나 컨트롤 플레인 파드의 리소스 할당을 늘리는(스케일 업) 방법으로 해결할 수 있음
트래픽 모니터링
트래픽은 컨트롤 플레인에 가해지는 부하를 의미하며 주로 RPS(Requests Per Second, 초당 요청 수)로 측정함
컨트롤 플레인의 트래픽은 크게 두 가지로 나눌 수 있음:
- 인커밍 트래픽: 설정 변경 관련 트래픽으로, 아래 메트릭으로 측정
- pilot_inbound_updates: 설정 변경 수신 횟수
- pilot_push_triggers: 푸시를 유발한 전체 이벤트 횟수
- pilot_services: Istiod가 인지하고 있는 서비스 개수
- Kubernetes API의 서비스 수와 일치
- 아웃고잉 트래픽: 데이터 플레인으로 설정을 푸시할 때 발생하는 트래픽으로, 아래 메트릭으로 측정
- xds_pushes: XDS(CDS, EDS, LDS, RDS) 푸시 횟수
- pilot_xds: 워크로드로의 전체 커넥션 개수
- Istio 사이드카 프록시가 실행 중인 파드의 수와 일치
- envoy_cluster_upstream_cx_tx_bytes_total: 네트워크로 전송된 설정 크기
오류 모니터링
오류는 실패율을 나타내며, 성능이 저하될 때 처리되지 못한 요청의 비율을 보여주고, "Pilot Errors" 패널에는 여러 오류 유형에 대한 메트릭이 포함되어 있음
- 설정 푸시 거부 횟수
- CDS, EDS, LDS, RDS 관련 오류
- 타임아웃
- 런타임 오류(주로 버그 관련)
컨트롤 플레인 성능 영향 요인
컨트롤 플레인 성능에 영향을 미치는 핵심 요인:
- 클러스터/환경의 변화 속도: 이벤트 발생 빈도와 처리 속도
- 컨트롤 플레인 리소스 할당량: CPU와 메모리 자원
- 워크로드 개수: 관리해야 할 워크로드 수
- 푸시된 설정의 크기: Envoy 구성 파일 크기
성능 최적화 방법:
- 서비스 메시와 관련 없는 이벤트 무시 설정
- 배치 처리 기간 조절
- 컨트롤 플레인 스케일 아웃/업
- 사이드카 설정을 통한 업데이트 분리
사이드카를 통한 최적화
모든 사이드카 프록시가 메시 내 모든 워크로드 정보를 갖고 있어 설정 크기가 매우 커질 수 있어서 다음과 같은 문제를 야기함
- 큰 메모리 사용량
- 네트워크 대역폭 낭비
- 불필요한 정보 공유로 인한 보안 위험
Istio의 Sidecar 리소스를 사용하여 각 프록시가 알아야 하는 정보를 제한할 수 있음
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: default
namespace: istio-system
spec:
egress:
- hosts:
- "./istio-system/*"
- "istio-system/*"
- "prometheus/*"- metadata.namespace: istio-system: 메시 전체에 적용
- egress.hosts: 지정된 네임스페이스로만 트래픽 허용
사이드카 적용 효과 확인
# 테스트를 위해 기본 네임스페이스에 nginx 배포
kubectl run nginx --image=nginx
# 사이드카 적용 전: 모든 프록시가 nginx 정보를 가짐
istioctl proxy-config route <pod-name> | grep nginx
istioctl proxy-config cluster <pod-name> | grep nginx
istioctl proxy-config endpoints <pod-name> | grep nginx
# 사이드카 적용
kubectl apply -f sidecar-global.yaml
# 사이드카 적용 후: nginx 정보가 사라짐
istioctl proxy-config route <pod-name> | grep nginx또한 설정 크기가 크게 감소하고, 성능 테스트 결과도 개선됨:
kubectl exec -it <pod-name> -c istio-proxy -- curl localhost:15000/config_dump > config-after.json
ls -lh config-after.json
# 약 1/4로 감소
이벤트 무시 최적화
Istio 컨트롤 플레인은 기본적으로 Kubernetes의 모든 네임스페이스에서 발생하는 파드, 서비스 등의 이벤트를 감지하며, 이는 불필요한 부하를 유발할 수 있음
DiscoverySelectors 설정
Istio 1.10부터 MeshConfig의 discoverySelectors를 사용하여 감시할 이벤트 범위를 제한할 수 있음
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
meshConfig:
discoverySelectors:
- matchLabels:
istio-discovery-enabled: "true"
- matchExpressions:
- key: istio-discovery-enabled
operator: DoesNotExist- istio-discovery-enabled: "true" 라벨이 있는 네임스페이스를 감시
- 또는 해당 라벨이 없는 네임스페이스를 감시
# 새 네임스페이스 생성 및 nginx 배포
kubectl create ns new-namespace
kubectl run nginx --image=nginx -n new-namespace
# 적용 전: nginx 정보가 프록시에 있음
istioctl proxy-config endpoints <pod-name> | grep new-namespace
# 라벨 추가로 이벤트 무시 설정
kubectl label namespace new-namespace istio-discovery-enabled=false
# 적용 후: nginx 정보가 사라짐
istioctl proxy-config endpoints <pod-name> | grep new-namespace
# 결과 없음디바운스 최적화
이벤트 발생 시 Istio는 다음과 같은 처리 과정을 거침(이 메커니즘은 빈번한 업데이트를 묶어서 효율적으로 처리):
- 이벤트 발생 → 디스커버리 서버가 받음
- 디바운스 대기 시간 동안 대기 (기본 100ms)
- 대기 시간 내 추가 이벤트 발생 시 타이머 리셋
- 최대 대기 시간 도달 또는 타이머 만료 시 큐에 추가
- 스로틀링 적용하여 푸시 처리
디바운스 관련 주요 환경변수:
- PILOT_DEBOUNCE_AFTER: 이벤트 발생 후 대기 시간 (기본 100ms)
- PILOT_DEBOUNCE_MAX: 최대 대기 시간 (기본 10초)
- PILOT_PUSH_THROTTLE: 동시 처리 푸시 요청 수 제한 (기본 100개)
디바운스 시간 조정 테스트
# 디바운스 시간을 2.5초로 늘림
kubectl set env deploy/istiod -n istio-system PILOT_DEBOUNCE_AFTER=2500
# 성능 테스트 실행
./performance-test.sh -n 10 -d 2.5- 디바운스 시간을 늘리면 푸시 횟수가 크게 감소하지만, 설정 변경이 적용되는데 더 오래 걸린다는 트레이드오프가 있음
- 디바운스 기간은 지연시간 메트릭에 포함되지 않는다는 점에 주의해야 함
컨트롤 플레인 스케일 아웃 시 주의사항
Istio 컨트롤 플레인을 스케일 아웃할 때 다음과 같은 문제가 있을 수 있음
- TCP 연결은 기본적으로 30분 유지
- 새로 생성된 컨트롤 플레인 파드로 기존 연결이 이동하지 않음
- 결과적으로 "플래핑" 현상 발생 가능 (스케일 아웃/인 반복)
이 문제를 완화하기 위한 설정:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: istiod-dr
namespace: istio-system
spec:
host: istiod.istio-system.svc.cluster.local
trafficPolicy:
connectionPool:
http:
maxConnectionAge: 1s # 기본 30분에서 변경용어 설명
- 데이터 플레인(Data Plane): 서비스 메시에서 실제 네트워크 트래픽을 처리하는 컴포넌트로, Istio에서는 Envoy 프록시가 이 역할을 담당
- 컨트롤 플레인(Control Plane): 서비스 메시의 구성과 정책을 관리하는 컴포넌트로, Istio에서는 istiod가 이 역할을 담당
- VirtualService: Istio의 라우팅 규칙을 정의하는 리소스로, 트래픽이 어떻게 라우팅될지를 설정
- DestinationRule: 트래픽이 목적지에 도달한 후 어떻게 처리될지 정의하는 리소스로, 로드 밸런싱 설정이나 서브셋 정의 등을 포함
- 서브셋(Subset): 동일한 서비스 내에서 다른 버전이나 변형을 정의하는 방법으로, 카나리 배포나 A/B 테스트 등에 사용됨
- SNI(Server Name Indication): TLS 확장 기능으로, 하나의 IP 주소에 여러 도메인을 호스팅할 때 클라이언트가 접속하려는 도메인을 서버에 알려주는 메커니즘
- 업스트림(Upstream): 프록시 기준으로 요청을 보내는 대상 서비스
- 다운스트림(Downstream): 프록시 기준으로 요청을 보낸 출발지 서비스
- 텔레메트리(Telemetry): 원격 시스템에서 데이터를 수집하고 모니터링하는 기술로, Istio에서는 서비스 메시의 동작 상태를 추적하는 데 사용
- 디바운스(Debounce): 짧은 시간 내에 반복적으로 발생하는 이벤트를 그룹화하여 한 번에 처리하는 기법
- 유령 워크로드(Ghost Workload): 실제로는 비정상적이지만 설정 업데이트 지연으로 인해 여전히 정상으로 인식되는 워크로드를 의미
- 이그레스(Egress): 서비스 메시에서 외부로 나가는 트래픽을 의미. 사이드카 설정에서는 아웃바운드 트래픽을 제어하는 데 사용됨
- 플래핑(Flapping): 시스템이 두 상태 사이를 빠르게 전환하는 현상으로, Istio에서는 컨트롤 플레인의 스케일 아웃/인이 반복되는 상황을 의미함
'Work > 개발 노트' 카테고리의 다른 글
| [Istio 스터디] 9주차 - Ambient Mesh (3) | 2025.06.08 |
|---|---|
| [Istio 스터디] 8주차 - VM Support & Istio Traffic Flow (0) | 2025.05.31 |
| [istio 스터디] 5주차 - 마이크로서비스 통신 보안 (0) | 2025.05.11 |
| [istio study] 4주차 - Observability (0) | 2025.05.03 |
| [Istio 스터디] 2주차 - Envoy, Istio Gateway (0) | 2025.04.19 |




댓글